
Автор: fitchguo, фоновый инженер-разработчик Tencent IEG.
Параллельное программирование всегда было одной из тем, которой разработчики уделяли наибольшее внимание. Как язык программирования с его собственным ореолом «высокого параллелизма» с момента его дебюта, принцип реализации параллельного программирования Golang определенно достоин нашего глубокого изучения.
Базовая модель параллельного программирования Go поддерживается библиотекой потоков, предоставляемой операционной системой.Здесь мы кратко представим концепции, связанные с моделью реализации потоков.
Модель реализации потока
Существуют три основные модели реализации потоков: модель потоков на уровне пользователя, модель потоков на уровне ядра и двухуровневая модель потоков. Самая большая разница между ними заключается в соответствии между пользовательскими потоками и объектами планирования ядра (KSE). Объект планирования ядра — это объект, который может быть запланирован планировщиком ядра операционной системы, также известный как поток уровня ядра, и является наименьшей единицей планирования ядра операционной системы.
Модель потоков на уровне пользователя
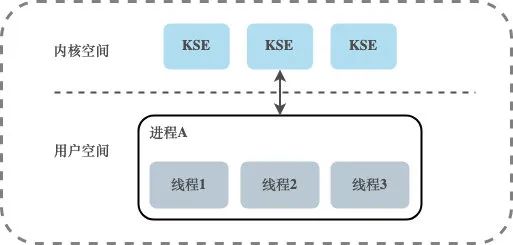
Между пользовательскими потоками и KSE существует отношение отображения «многие к одному» (N:1). Потоки в этой модели полностью управляются библиотекой потоков пользовательского уровня, которая хранится в пользовательском пространстве процесса Существование этих потоков незаметно для ядра, поэтому эти потоки не являются объектами, запланированными планировщиком ядра. Все потоки, созданные в процессе, только динамически привязываются к одному и тому же KSE во время выполнения, и все планирование ядра основано на пользовательских процессах.
Планирование потоков выполняется на уровне пользователя.По сравнению с планированием ядра, оно не требует переключения ЦП между пользовательским режимом и режимом ядра.По сравнению с моделью потоков на уровне ядра, этот метод реализации может быть очень легким.Потребление системных ресурсов будет намного меньше, и стоимость переключения контекста будет намного меньше. Библиотеки сопрограмм, реализованные на многих языках, в основном попадают в эту категорию. Однако многопоточность в этой модели не может работать одновременно. Например, если поток блокируется во время операции ввода-вывода, блокируются все потоки в его собственном процессе, и весь процесс приостанавливается.
Модель потоков на уровне ядра
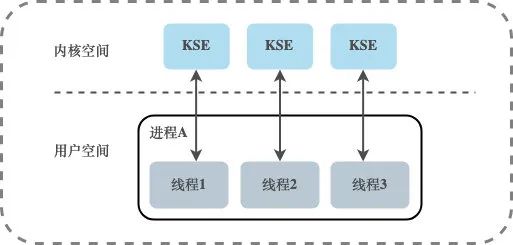
Между пользовательскими потоками и KSE существует взаимосвязь отображения один к одному (1:1). Потоки в этой модели управляются ядром. Создание, завершение и синхронизация потоков приложения должны выполняться с помощью системных вызовов, предоставляемых ядром. Ядро может планировать каждый поток отдельно. Следовательно, модель потоков «один-к-одному» действительно может реализовать параллельный запуск потоков, и большинство библиотек потоков, реализованных языками, в основном относятся к этому методу. Однако создание, переключение и синхронизация потоков в этой модели требуют больше ресурсов ядра и времени.Если процесс содержит большое количество потоков, это создаст большую нагрузку на планировщик ядра и даже повлияет на общую производительность системы. операционная система.
Двухуровневая модель потоков
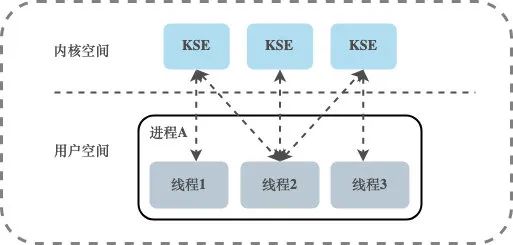
Между пользовательскими потоками и KSE существует отношение отображения «многие ко многим» (N:M). Двухуровневая модель потоков поглощает преимущества первых двух моделей потоков и максимально избегает их недостатков.В отличие от модели потоков на уровне пользователя, процесс в двухуровневой модели потоков может быть связан с несколькими потоками ядра KSE. , то есть процесс внутри процесса. Несколько потоков могут быть привязаны к их собственной KSE, что похоже на модель потоков на уровне ядра; во-вторых, она отличается от модели потоков на уровне ядра. процесс не привязан однозначно к KSE, но может быть несколько пользовательских потоков, сопоставленных с одним и тем же KSE.Когда KSE запланировано вне ЦП ядром из-за операции блокировки его связанного потока, оставшиеся пользовательские потоки в связанном процесс может повторно связываться с другими KSE для запуска. Таким образом, двухуровневая модель потока не является ни моделью потока на уровне пользователя, которая полностью планируется сама по себе, ни моделью потока на уровне ядра, которая полностью планируется операционной системой, а является промежуточным состоянием, в котором собственное планирование и планирование системы работать вместе, то есть пользовательское планирование Планировщик ядра реализует планирование от KSE до ЦП.
Параллелизм в Go
В модели параллельного программирования Go независимые потоки управления, которые не управляются ядром операционной системы, называются не пользовательскими потоками или потоками, а горутинами. Goroutine обычно рассматривается как реализация сопрограммы Go. На самом деле Goroutine не является сопрограммой в традиционном смысле. Традиционная библиотека сопрограммы относится к модели потоков пользовательского уровня, а базовая реализация Goroutine в сочетании с планировщиком Go принадлежит модель двухуровневой нити.
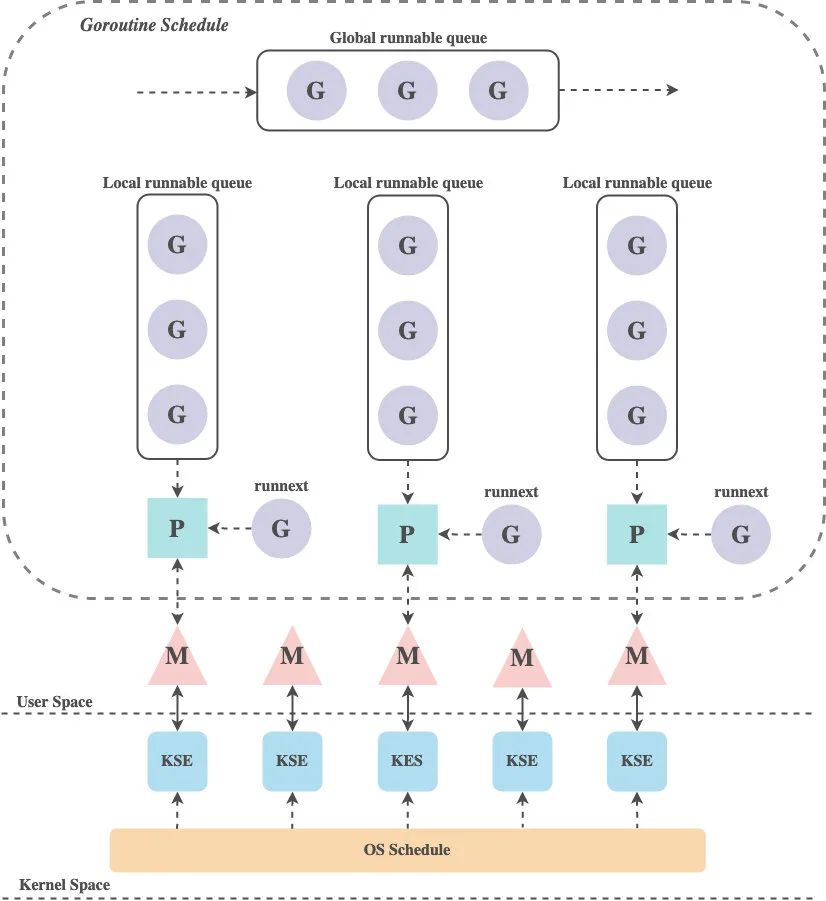
Go строит уникальную двухуровневую модель многопоточности. Планировщик Go реализует планирование из Goroutine в KSE, а планировщик ядра реализует планирование из KSE в ЦП. Планировщик Go использует три структуры G, M и P для реализации планирования Goroutine, также известного как модель GMP .
Модель GMP
G : Указывает Горутин. Каждая горутина соответствует структуре G, а G хранит рабочий стек, состояние и функции задач горутины, которые можно использовать повторно. Когда горутина передается от ЦП, код планировщика отвечает за сохранение значения регистра ЦП в переменной-члене объекта G, а когда горутина запланирована для запуска, код планировщика отвечает за сохранение сохраненного регистра. в переменной-члене объекта G восстановить значение в регистр ЦП
M : абстракция базового потока ОС, который сам связан с потоком ядра, и каждый рабочий поток имеет уникальный объект-экземпляр соответствующей ему структуры M, который представляет реальные вычислительные ресурсы и управляется операционная система Планировщик для планирования и управления. В дополнение к записи информации о состоянии рабочего потока, такой как начальная и конечная позиция стека, выполняемая в данный момент горутина и ее бездействие, объект структуры M также поддерживает связь привязки с объектом экземпляра структуры P. через указатель
P : Указывает на логический процессор. Для G P эквивалентен ядру ЦП, а G можно планировать только в том случае, если он привязан к P (в локальном runq P). Для M P предоставляет соответствующую среду выполнения (Context), такую как состояние выделения памяти (mcache), очередь задач (G) и так далее. Он поддерживает локальную очередь выполнения G. Рабочие потоки предпочтительно используют свои собственные локальные очереди выполнения и обращаются к глобальной очереди выполнения только при необходимости. Это может значительно уменьшить конфликты блокировок, улучшить параллелизм рабочих потоков и может быть хорошо использовано. локализация программ
Выполнение G требует поддержки P и M. После того, как M связан с P, формируется эффективная рабочая среда G (поток ядра + контекст). Каждый P содержит очередь (runq) исполняемых G. G в очереди будет передан в M, связанный с локальным P, в свою очередь, и получит время выполнения.
Между M и KSE всегда существует однозначное соответствие, и один M может представлять только один поток ядра. Связь между M и KSE очень стабильна, в течение своего жизненного цикла M будет связана только с одной KSE, а связь между M и P, P и G изменчива, а M и P также взаимно однозначны. отношения, P и G - отношения один ко многим.
грамм
Во время выполнения G имеет тот же статус в планировщике, что и потоки в операционной системе, но занимает меньше места в памяти и уменьшает накладные расходы на переключение контекста. Это поток, предоставляемый языком Go в пользовательском режиме.Как более мелкозернистая единица планирования ресурсов, при правильном использовании он может более эффективно использовать ЦП машины в сценариях с высокой степенью параллелизма.
Исходный код части структуры g (src/runtime/runtime2.go):
type g struct {
stack stack // Goroutine的栈内存范围[stack.lo, stack.hi)
stackguard0 uintptr // 用于调度器抢占式调度
m *m // Goroutine占用的线程
sched gobuf // Goroutine的调度相关数据
atomicstatus uint32 // Goroutine的状态
...
}
type gobuf struct {
sp uintptr // 栈指针
pc uintptr // 程序计数器
g guintptr // gobuf对应的Goroutine
ret sys.Uintewg // 系统调用的返回值
...
}
Содержимое, сохраненное в gobuf, используется, когда планировщик сохраняет или восстанавливает контекст, где указатель стека и программный счетчик используются для сохранения или восстановления значения в регистре, изменяя код, который программа собирается выполнить.
В поле atomicstatus хранится статус текущей горутины.Горутина может находиться в следующих состояниях:
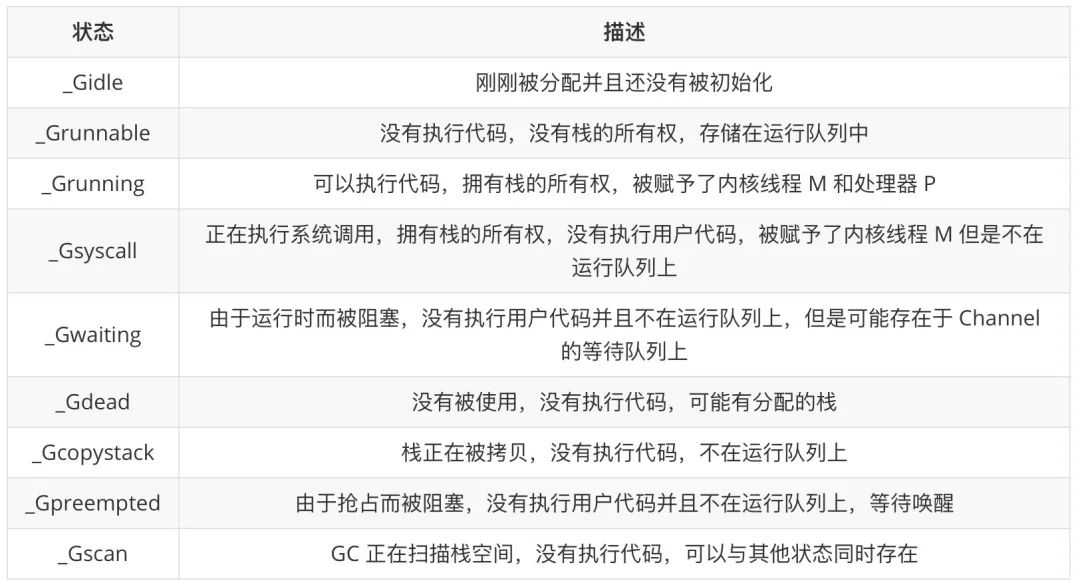
Переход состояния горутины — очень сложный процесс, и существует много способов инициировать переход состояния. Здесь мы в основном вводим пять общих состояний _Grunnable, _Grunning, _Gsyscall, _Gwaiting и _Gpreempted.
Эти различные состояния могут быть объединены в три состояния: ожидание, готовность к работе и выполнение, переключение между этими тремя состояниями во время работы:
-
Ожидание: горутина ожидает выполнения определенных условий, таких как завершение системных вызовов и т. д., включая состояния _Gwaiting, _Gsyscall и _Gpreempted. -
Runnable: горутины готовы к запуску в потоках.Если в текущей программе много горутин, каждая горутина может ждать больше времени, т. е. _Grunnable -
Запуск: Goroutine работает в потоке, т.е. _Grunning
G Общая схема перехода состояний:
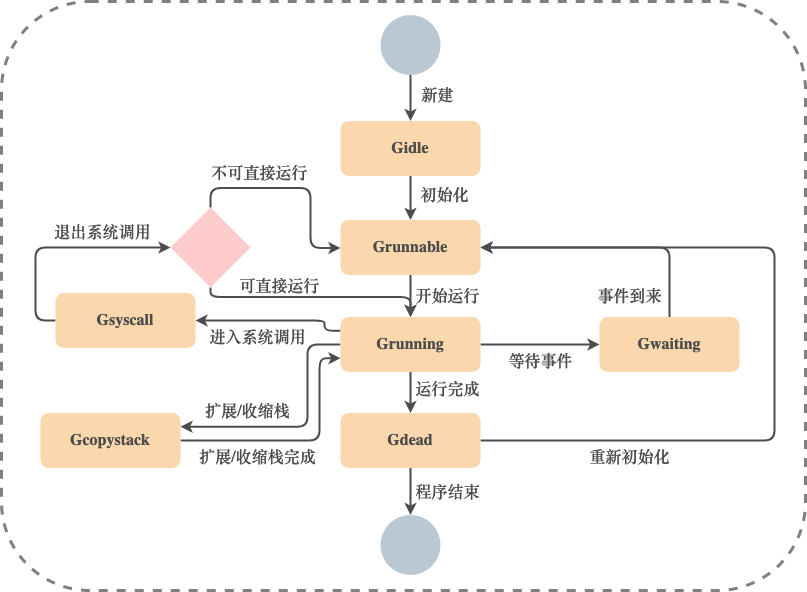
G, который входит в мертвое состояние, может быть повторно инициализирован и использован.
М
Модель параллелизма M in Go представляет собой поток операционной системы. Планировщик может создать до 10 000 потоков, но только не более GOMAXPROCS (количество P) активных потоков могут работать нормально. По умолчанию среда выполнения установит GOMAXPROCS на количество ядер на текущей машине.Мы также можем использовать runtime.GOMAXPROCS в программе, чтобы изменить максимальное количество активных потоков.
Например, для четырехъядерной машины среда выполнения создаст четыре активных потока операционной системы, каждый из которых соответствует структуре runtime.m в среде выполнения. В большинстве случаев мы будем использовать настройку Go по умолчанию, т. е. количество потоков равно количеству ЦП. Настройка по умолчанию не будет часто запускать планирование потоков и переключение контекста операционной системы. Все планирование будет происходить в пользовательский режим, предоставляемый языком Go. Планировщик запускает триггеры, что может сократить дополнительные накладные расходы.
исходный код структуры m (часть):
type m struct {
g0 *g // 一个特殊的goroutine,执行一些运行时任务
gsignal *g // 处理signal的G
curg *g // 当前M正在运行的G的指针
p puintptr // 正在与当前M关联的P
nextp puintptr // 与当前M潜在关联的P
oldp puintptr // 执行系统调用之前使用线程的P
spinning bool // 当前M是否正在寻找可运行的G
lockedg *g // 与当前M锁定的G
}
g0 представляет собой специальную горутину, созданную исполняющей системой Go, в которой она запускается, и она глубоко вовлечена в процесс планирования времени выполнения, включая создание горутины, выделение большого объема памяти и выполнение функции CGO. curg — пользовательская горутина, работающая в текущем потоке.
п
Процессор P в планировщике является средним уровнем между потоками и горутинами.Он может предоставлять контекст, требуемый потоком, а также отвечает за планирование очереди ожидания в потоке.Благодаря планированию процессора P каждый поток ядра может выполнять несколько горутин, он может отказаться от вычислительных ресурсов вовремя, когда горутина выполняет некоторые операции ввода-вывода, и улучшить использование потоков.
Количество P равно GOMAXPROCS, и установка значения GOMAXPROCS может ограничивать только максимальное количество P, а на количество M и G ограничений нет. Когда G, работающий на M, вводит системный вызов и вызывает блокировку M, система среды выполнения отделит M от связанного с ним P. В это время, если все еще есть незапущенные очереди G в готовой к выполнению очереди G G, затем система найдет незанятый M во время выполнения или создаст новый M, связанный с P, для удовлетворения текущих потребностей этих G. Поэтому количество М часто больше, чем Р.
исходный код структуры p (часть):
type p struct {
// p 的状态
status uint32
// 对应关联的 M
m muintptr
// 可运行的Goroutine队列,可无锁访问
runqhead uint32
runqtail uint32
runq [256]guintptr
// 缓存可立即执行的G
runnext guintptr
// 可用的G列表,G状态等于Gdead
gFree struct {
gList
n int32
}
...
}
Состояния, в которых может находиться P, следующие:
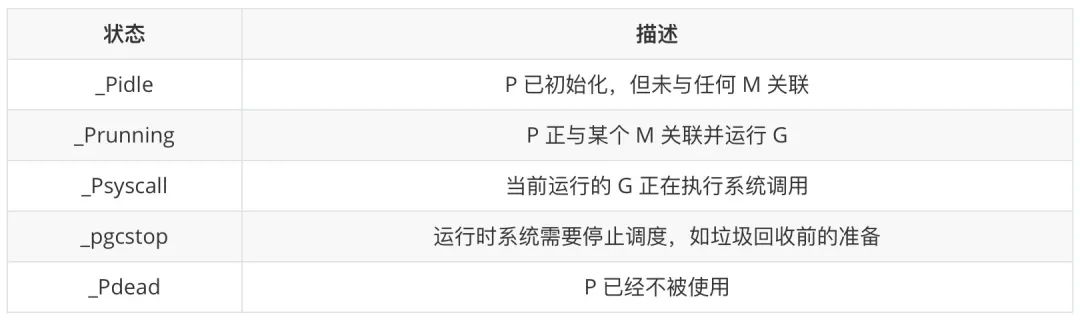
планировщик
Некоторые задачи планирования в двухуровневой поточной модели выполняются программами вне операционной системы. В языке Go за эту часть планирования задач отвечает планировщик. Основными объектами планирования являются экземпляры G, M и P. Каждый M (то есть каждый поток ядра) будет выполнять некоторые задачи планирования во время запущенного процесса, и они совместно реализуют функцию планирования планировщика Go.
г0 и м0
Каждый M в системе выполнения будет иметь специальный G, обычно называемый M's g0. g0 для M не генерируется косвенно кодом в программе Go, а создается и назначается M системой выполнения Go при ее инициализации. g0 of M обычно используется для выполнения таких задач, как планирование, сборка мусора и управление стеком. M также будет иметь G, предназначенный для обработки сигналов, называемый gsignal.
За исключением g0 и gsignal, другие G, управляемые M, могут рассматриваться как G уровня пользователя, для краткости называемые пользователем G, а g0 и gsignal могут называться системой G. Система выполнения Go переключается, так что каждый M может попеременно запускать пользователя G и его g0. Вот почему раньше "каждый М запускает планировщик".
В дополнение к тому, что у каждого M есть свой g0, есть еще runtime.g0. runtime.g0 используется для выполнения программы начальной загрузки.Он выполняется в первом потоке ядра, принадлежащем программе Go.Этот поток также называется runtime.m0.g0 из runtime.m0 называется runtime.g0.
Контейнер для основных элементов
Выше обсуждались три основных элемента модели реализации потоков Go — G, M и P. Давайте взглянем на контейнеры, содержащие экземпляры этих элементов:
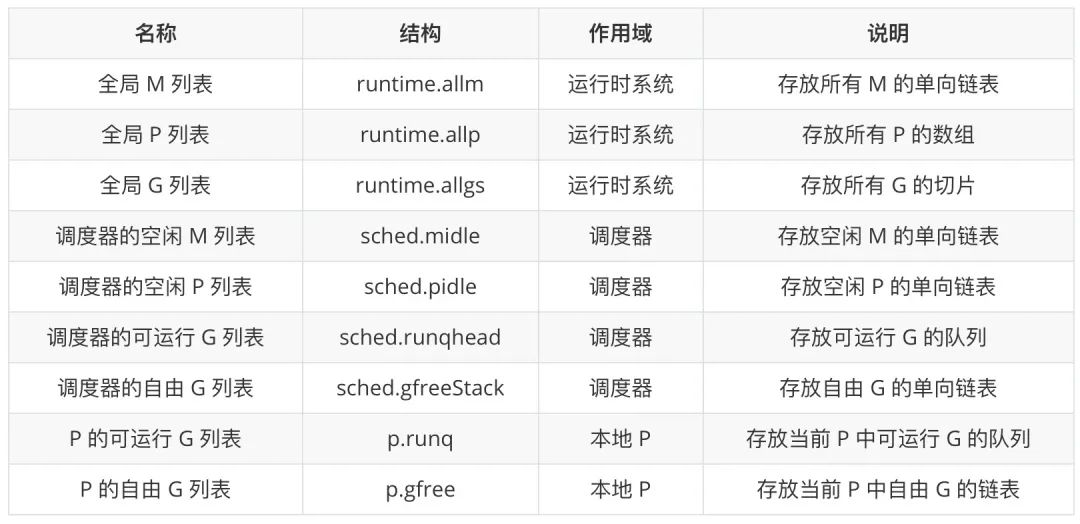
Особого внимания заслуживают четыре контейнера, относящиеся к G. Любой G будет существовать в глобальном списке G, а оставшиеся четыре контейнера будут хранить только G в текущей области видимости и с определенным состоянием. G в двух исполняемых списках G имеют почти равные возможности для запуска, но планирование в разное время поместит G в разные места. Запустите очередь G, и только что инициализированный G будет помещен в исполняемую очередь G местный П. Кроме того, две исполняемые очереди G также будут передавать друг другу G. Например, когда локальная исполняемая очередь G заполнена, половина G будет передана в исполняемую очередь G планировщика.
Список свободных M и список свободных P планировщика используются для хранения временно неиспользуемых экземпляров элементов. Когда система времени выполнения нуждается в этом, она получает от него экземпляр соответствующего элемента и повторно включает его.
цикл расписания
Вызовите runtime.schedule, чтобы войти в цикл планирования:
func schedule() {
_g_ := getg()
top:
var gp *g
var inheritTime bool
if gp == nil {
// 为了公平,每调用schedule函数61次就要从全局可运行G队列中获取
if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
gp = globrunqget(_g_.m.p.ptr(), 1)
unlock(&sched.lock)
}
}
// 从P本地获取G任务
if gp == nil {
gp, inheritTime = runqget(_g_.m.p.ptr())
}
// 运行到这里表示从本地运行队列和全局运行队列都没有找到需要运行的G
if gp == nil {
// 阻塞地查找可用G
gp, inheritTime = findrunnable()
}
// 执行G任务函数
execute(gp, inheritTime)
}
Функция runtime.schedule ищет горутины для выполнения из следующих мест:
-
Чтобы обеспечить справедливость, когда в глобальной очереди выполнения есть горутины для выполнения, schedtick гарантирует, что существует определенная вероятность того, что соответствующая горутина будет найдена в глобальной очереди выполнения. -
Найдите горутину, которую нужно выполнить, из очереди выполнения, локальной для процессора. -
Если первые два метода не найдут G, он будет использовать функцию findrunnable, чтобы «украсть» некоторое количество G у других P для его выполнения.
Затем полученная горутина выполняется runtime.execute:
func execute(gp *g, inheritTime bool) {
_g_ := getg()
// 将G绑定到当前M上
_g_.m.curg = gp
gp.m = _g_.m
// 将g正式切换为_Grunning状态
casgstatus(gp, _Grunnable, _Grunning)
gp.waitsince = 0
// 抢占信号
gp.preempt = false
gp.stackguard0 = gp.stack.lo + _StackGuard
if !inheritTime {
// 调度器调度次数增加1
_g_.m.p.ptr().schedtick++
}
...
// gogo完成从g0到gp的切换
gogo(&gp.sched)
}
При выполнении execute G будет переключен в состояние _Grunning, а M и G будут связаны, и, наконец, будет вызван runtime.gogo, чтобы запланировать выполнение Goroutine в текущем потоке. runtime.gogo возьмет программный счетчик из runtime.goexit и программный счетчик функции, которая должна быть выполнена из runtime.gobuf, и будет:
-
Счетчик программ runtime.goexit размещается на стеке SP -
Счетчик программ выполняемой функции помещается в регистр BX.
MOVL gobuf_sp(BX), SP // 将runtime.goexit函数的PC恢复到SP中
MOVL gobuf_pc(BX), BX // 获取待执行函数的程序计数器
JMP BX // 开始执行
Когда функция, работающая в горутине, вернется, программа перейдет к местоположению runtime.goexit и, наконец, вызовет функцию runtime.goexit0 в стеке g0 текущего потока, которая преобразует горутину в состояние _Gdead и очистит поднимите поля в нем, удалите связь между Goroutine и потоком и вызовите runtime.gfput, чтобы повторно добавить G в список свободных Goroutine процессора gFree:
func goexit0(gp *g) {
_g_ := getg()
// 设置当前G状态为_Gdead
casgstatus(gp, _Grunning, _Gdead)
// 清理G
gp.m = nil
...
gp.writebuf = nil
gp.waitreason = 0
gp.param = nil
gp.labels = nil
gp.timer = nil
// 解绑M和G
dropg()
...
// 将G扔进gfree链表中等待复用
gfput(_g_.m.p.ptr(), gp)
// 再次进行调度
schedule()
}
Наконец, runtime.goexit0 снова вызовет runtime.schedule, чтобы запустить новый раунд планирования Goroutine.Планировщик начинается с runtime.schedule и, наконец, возвращается к runtime.schedule, который является циклом планирования языка Go.
Канал
Шаблон проектирования, который часто упоминается в Go: не обменивайтесь информацией, разделяя память, а делитесь памятью посредством связи. Горутины передают данные через каналы.Как основная структура данных языка Go и метод связи между горутинами, канал является важной структурой, поддерживающей высокопроизводительную модель параллельного программирования языка Go.
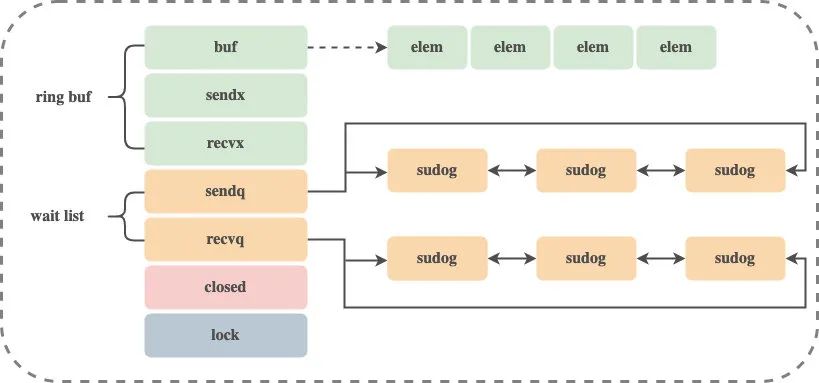
Внутренним представлением канала во время выполнения является runtime.hchan, который содержит мьютекс для защиты переменных-членов.В определенной степени канал представляет собой заблокированную очередь для синхронизации и связи. Исходный код структуры hchan:
type hchan struct {
qcount uint // 循环列表元素个数
dataqsiz uint // 循环队列的大小
buf unsafe.Pointer // 循环队列的指针
elemsize uint16 // chan中元素的大小
closed uint32 // 是否已close
elemtype *_type // chan中元素类型
sendx uint // chan的发送操作处理到的位置
recvx uint // chan的接收操作处理到的位置
recvq waitq // 等待接收数据的Goroutine列表
sendq waitq // 等待发送数据的Goroutine列表
lock mutex // 互斥锁
}
type waitq struct { // 双向链表
first *sudog
last *sudog
}
В waitq подключен двусвязный список sudog, который сохраняет ожидающую горутину.
создать чан
Используйте ключевое слово make для создания конвейера, make(chan int, 3) будет вызываться в функции runtime.makechan:
const (
maxAlign = 8
hchanSize = unsafe.Sizeof(hchan{}) + uintptr(-int(unsafe.Sizeof(hchan{}))&(maxAlign-1))
)
func makechan(t *chantype, size int) *hchan {
elem := t.elem
// 计算需要分配的buf空间大小
mem, overflow := math.MulUintptr(elem.size, uintptr(size))
if overflow || mem > maxAlloc-hchanSize || size < 0 {
panic(plainError("makechan: size out of range"))
}
var c *hchan
switch {
case mem == 0:
// chan的大小或者elem的大小为0,不需要创建buf
c = (*hchan)(mallocgc(hchanSize, nil, true))
// Race detector uses this location for synchronization.
c.buf = c.raceaddr()
case elem.ptrdata == 0:
// elem不含指针,分配一块连续的内存给hchan数据结构和buf
c = (*hchan)(mallocgc(hchanSize+mem, nil, true))
c.buf = add(unsafe.Pointer(c), hchanSize)
default:
// elem包含指针,单独分配buf
c = new(hchan)
c.buf = mallocgc(mem, elem, true)
}
// 更新hchan的elemsize、elemtype、dataqsiz字段
c.elemsize = uint16(elem.size)
c.elemtype = elem
c.dataqsiz = uint(size)
return c
}
Приведенный выше код инициализирует runtime.hchan и буфер в соответствии с типом элементов отправки и получения в канале и размером буфера:
-
Если требуемый размер буфера равен 0, под хчан будет выделен только участок памяти -
Если требуемый размер буфера не равен 0 и elem не содержит указателя, для hchan и buf будет выделен непрерывный участок памяти. -
若缓冲区所需大小不为 0 且 elem 包含指针,会单独为 hchan 和 buf 分配内存
发送数据到 chan
发送数据到 channel,ch <- i 会调用到 runtime.chansend 函数中,该函数包含了发送数据的全部逻辑:
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
if c == nil {
// 对于非阻塞的发送,直接返回
if !block {
return false
}
// 对于阻塞的通道,将goroutine挂起
gopark(nil, nil, waitReasonChanSendNilChan, traceEvGoStop, 2)
throw("unreachable")
}
// 加锁
lock(&c.lock)
// channel已关闭,panic
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("send on closed channel"))
}
...
}
block 表示当前的发送操作是否是阻塞调用。如果 channel 为空,对于非阻塞的发送,直接返回 false,对于阻塞的发送,将 goroutine 挂起,并且永远不会返回。对 channel 加锁,防止多个线程并发修改数据,如果 channel 已关闭,报错并中止程序。
runtime.chansend 函数的执行过程可以分为以下三个部分:
-
当存在等待的接收者时,通过 runtime.send 直接将数据发送给阻塞的接收者 -
当缓冲区存在空余空间时,将发送的数据写入缓冲区 -
当不存在缓冲区或缓冲区已满时,等待其他 Goroutine 从 channel 接收数据
直接发送
如果目标 channel 没有被关闭且 recvq 队列中已经有处于读等待的 Goroutine,那么 runtime.chansend 会从接收队列 recvq 中取出最先陷入等待的 Goroutine 并直接向它发送数据,注意,由于有接收者在等待,所以如果有缓冲区,那么缓冲区一定是空的:
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
...
// 从recvq中取出一个接收者
if sg := c.recvq.dequeue(); sg != nil {
// 如果接收者存在,直接向该接收者发送数据,绕过buf
send(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true
}
...
}
直接发送会调用 runtime.send 函数:
func send(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
...
if sg.elem != nil {
// 直接把要发送的数据copy到接收者的栈空间
sendDirect(c.elemtype, sg, ep)
sg.elem = nil
}
gp := sg.g
unlockf()
gp.param = unsafe.Pointer(sg)
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
// 设置对应的goroutine为可运行状态
goready(gp, skip+1)
}
sendDirect 方法调用 memmove 进行数据的内存拷贝。goready 方法将等待接收数据的 Goroutine 标记成可运行状态(Grunnable)并把该 Goroutine 发到发送方所在的处理器的 runnext 上等待执行,该处理器在下一次调度时会立刻唤醒数据的接收方。注意,只是放到了 runnext 中,并没有立刻执行该 Goroutine。
发送到缓冲区
如果缓冲区未满,则将数据写入缓冲区:
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
...
// 如果缓冲区没有满,直接将要发送的数据复制到缓冲区
if c.qcount < c.dataqsiz {
// 找到buf要填充数据的索引位置
qp := chanbuf(c, c.sendx)
...
// 将数据拷贝到buf中
typedmemmove(c.elemtype, qp, ep)
// 数据索引前移,如果到了末尾,又从0开始
c.sendx++
if c.sendx == c.dataqsiz {
c.sendx = 0
}
// 元素个数加1,释放锁并返回
c.qcount++
unlock(&c.lock)
return true
}
...
}
找到缓冲区要填充数据的索引位置,调用 typedmemmove 方法将数据拷贝到缓冲区中,然后重新设值 sendx 偏移量。
阻塞发送
当 channel 没有接收者能够处理数据时,向 channel 发送数据会被下游阻塞,使用 select 关键字可以向 channel 非阻塞地发送消息:
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
...
// 缓冲区没有空间了,对于非阻塞调用直接返回
if !block {
unlock(&c.lock)
return false
}
// 创建sudog对象
gp := getg()
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
mysg.elem = ep
mysg.waitlink = nil
mysg.g = gp
mysg.isSelect = false
mysg.c = c
gp.waiting = mysg
gp.param = nil
// 将sudog对象入队
c.sendq.enqueue(mysg)
// 进入等待状态
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanSend, traceEvGoBlockSend, 2)
...
}
对于非阻塞的调用会直接返回,对于阻塞的调用会创建 sudog 对象并将 sudog 对象加入发送等待队列。调用 gopark 将当前 Goroutine 转入 waiting 状态。调用 gopark 之后,在使用者看来向该 channel 发送数据的代码语句会被阻塞。
发送数据整个流程大致如下:
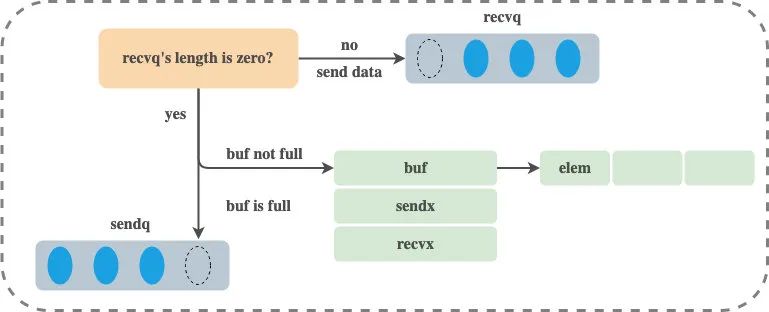
注意,发送数据的过程中包含几个会触发 Goroutine 调度的时机:
-
发送数据时发现从 channel 上存在等待接收数据的 Goroutine,立刻设置处理器的 runnext 属性,但是并不会立刻触发调度 -
发送数据时并没有找到接收方并且缓冲区已经满了,这时会将自己加入 channel 的 sendq 队列并调用 gopark 触发 Goroutine 的调度让出处理器的使用权
从 chan 接收数据
从 channel 获取数据最终调用到 runtime.chanrecv 函数:
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
if c == nil {
// 如果c为空且是非阻塞调用,直接返回
if !block {
return
}
// 阻塞调用直接等待
gopark(nil, nil, waitReasonChanReceiveNilChan, traceEvGoStop, 2)
throw("unreachable")
}
···
lock(&c.lock)
// 如果c已经关闭,并且c中没有数据,返回
if c.closed != 0 && c.qcount == 0 {
unlock(&c.lock)
if ep != nil {
typedmemclr(c.elemtype, ep)
}
return true, false
}
···
}
当从一个空 channel 接收数据时,直接调用 gopark 让出处理器使用权。如果当前 channel 已被关闭且缓冲区中没有数据,直接返回。
runtime.chanrecv 函数的具体执行过程可以分为以下三个部分:
-
当存在等待的发送者时,通过 runtime.recv 从阻塞的发送者或者缓冲区中获取数据 -
当缓冲区存在数据时,从 channel 的缓冲区中接收数据 -
当缓冲区中不存在数据时,等待其他 Goroutine 向 channel 发送数据
直接接收
当 channel 的 sendq 队列中包含处于发送等待状态的 Goroutine 时,调用 runtime.recv 直接从这个发送者那里提取数据。注意,由于有发送者在等待,所以如果有缓冲区,那么缓冲区一定是满的。
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
...
// 从发送者队列获取数据
if sg := c.sendq.dequeue(); sg != nil {
// 发送者队列不为空,直接从发送者那里提取数据
recv(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true, true
}
...
}
主要看一下 runtime.recv 的实现:
func recv(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
// 如果是无缓冲区chan
if c.dataqsiz == 0 {
if ep != nil {
// 直接从发送者拷贝数据
recvDirect(c.elemtype, sg, ep)
}
// 有缓冲区chan
} else {
// 获取buf的存放数据指针
qp := chanbuf(c, c.recvx)
// 直接从缓冲区拷贝数据给接收者
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
// 从发送者拷贝数据到缓冲区
typedmemmove(c.elemtype, qp, sg.elem)
c.recvx++
c.sendx = c.recvx // c.sendx = (c.sendx+1) % c.dataqsiz
}
gp := sg.g
gp.param = unsafe.Pointer(sg)
// 设置对应的goroutine为可运行状态
goready(gp, skip+1)
}
该函数会根据缓冲区的大小分别处理不同的情况:
-
如果 channel 不存在缓冲区 -
直接从发送者那里提取数据 -
如果 channel 存在缓冲区 -
将缓冲区中的数据拷贝到接收方的内存地址 -
将发送者数据拷贝到缓冲区,并唤醒发送者
无论发生哪种情况,运行时都会调用 goready 将等待发送数据的 Goroutine 标记成可运行状态(Grunnable)并将当前处理器的 runnext 设置成发送数据的 Goroutine,在调度器下一次调度时将阻塞的发送方唤醒。
从缓冲区接收
如果 channel 缓冲区中有数据且发送者队列中没有等待发送的 Goroutine 时,直接从缓冲区中 recvx 的索引位置取出数据:
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
...
// 如果缓冲区中有数据
if c.qcount > 0 {
qp := chanbuf(c, c.recvx)
// 从缓冲区复制数据到ep
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
typedmemclr(c.elemtype, qp)
// 接收数据的指针前移
c.recvx++
// 环形队列,如果到了末尾,再从0开始
if c.recvx == c.dataqsiz {
c.recvx = 0
}
// 缓冲区中现存数据减一
c.qcount--
unlock(&c.lock)
return true, true
}
...
}
阻塞接收
当 channel 的发送队列中不存在等待的 Goroutine 并且缓冲区中也不存在任何数据时,从管道中接收数据的操作会被阻塞,使用 select 关键字可以非阻塞地接收消息:
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
...
// 非阻塞,直接返回
if !block {
unlock(&c.lock)
return false, false
}
// 创建sudog
gp := getg()
mysg := acquireSudog()
···
gp.waiting = mysg
mysg.g = gp
mysg.isSelect = false
mysg.c = c
gp.param = nil
// 将sudog添加到等待接收队列中
c.recvq.enqueue(mysg)
// 阻塞Goroutine,等待被唤醒
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanReceive, traceEvGoBlockRecv, 2)
...
}
如果是非阻塞调用,直接返回。阻塞调用会将当前 Goroutine 封装成 sudog,然后将 sudog 添加到等待接收队列中,调用 gopark 让出处理器的使用权并等待调度器的调度。
注意,接收数据的过程中包含几个会触发 Goroutine 调度的时机:
-
当 channel 为空时 -
当 channel 的缓冲区中不存在数据并且 sendq 中也不存在等待的发送者时
关闭 chan
关闭通道会调用到 runtime.closechan 方法:
func closechan(c *hchan) {
// 校验逻辑
...
lock(&c.lock)
// 设置chan已关闭
c.closed = 1
var glist gList
// 获取所有接收者
for {
sg := c.recvq.dequeue()
if sg == nil {
break
}
if sg.elem != nil {
typedmemclr(c.elemtype, sg.elem)
sg.elem = nil
}
gp := sg.g
gp.param = nil
glist.push(gp)
}
// 获取所有发送者
for {
sg := c.sendq.dequeue()
...
}
unlock(&c.lock)
// 唤醒所有glist中的goroutine
for !glist.empty() {
gp := glist.pop()
gp.schedlink = 0
goready(gp, 3)
}
}
将 recvq 和 sendq 两个队列中的 Goroutine 加入到 gList 中,并清除所有 sudog 上未被处理的元素。最后将所有 glist 中的 Goroutine 加入调度队列,等待被唤醒。注意,发送者在被唤醒之后会 panic。
总结一下发送/接收/关闭操作可能引发的结果:
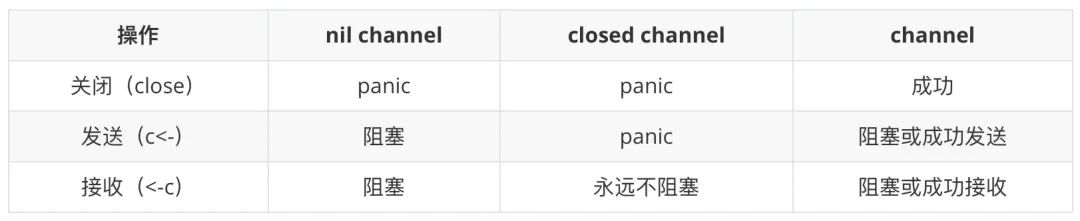
Goroutine 和 channel 的实现共同支撑起了 Go 语言的并发机制。
近期好文:
