
Оригинальная ссылка: http://33h.co/kyq4z
Часть 1 Оптимизация производительности Linux
1оптимизация производительности
Производительность
Высокий параллелизм и быстрый отклик соответствуют двум основным показателям оптимизации производительности: пропускной способности и задержке .

-
Перспектива загрузки приложения : напрямую влияет на работу пользователя с терминалом продукта. -
Перспектива системных ресурсов : использование ресурсов, насыщение и т. д.
Суть проблемы с производительностью в том, что системные ресурсы достигли узкого места, но обработка запросов недостаточно быстрая, чтобы поддерживать большее количество запросов. Анализ производительности на самом деле заключается в том, чтобы найти узкие места в приложении или системе и попытаться их избежать или смягчить.
-
Выберите метрики для оценки производительности приложений и системы -
Установите цели производительности для приложений и систем -
Делайте тесты производительности -
Анализ производительности для выявления узких мест -
Мониторинг производительности и оповещение
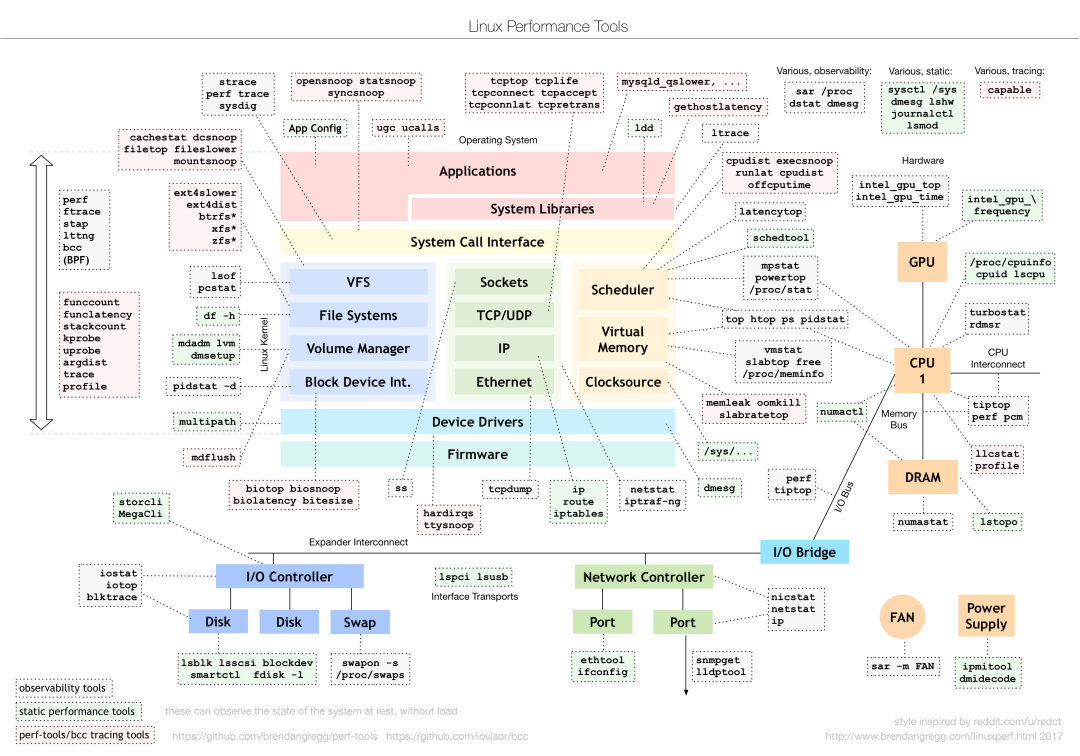
Для различных проблем с производительностью следует выбирать разные инструменты анализа производительности. Ниже приведены часто используемые инструменты повышения производительности Linux и анализируются соответствующие типы проблем с производительностью.
Как следует понимать «среднюю нагрузку»?
Средняя нагрузка: среднее количество процессов, которые система находится в работающем состоянии и состоянии бесперебойного питания в единицу времени, то есть среднее количество активных процессов. Это не связано напрямую с использованием процессора, как мы его традиционно понимаем.
Непрерываемый процесс — это процесс, который находится в ключевом процессе режима ядра (например, общий ответ ввода-вывода, ожидающий устройства). Непрерывное состояние на самом деле является механизмом защиты системы для обработки и аппаратных устройств.
разумная средняя нагрузка
В реальной производственной среде отслеживается средняя нагрузка системы, и тенденция изменения нагрузки оценивается в соответствии с историческими данными. При наличии очевидной тенденции к увеличению нагрузки проводится своевременный анализ и расследование. Конечно, вы также можете установить порог (например, когда средняя загрузка превышает 70% от количества процессоров).
В реальной работе мы часто путаем понятия средней нагрузки и использования ЦП, но они не совсем эквивалентны:
-
Процесс с интенсивным использованием ЦП, большая загрузка ЦП приведет к увеличению средней нагрузки, в настоящее время они совпадают. -
Процессы с интенсивным вводом-выводом, ожидающие ввода-вывода, также увеличат среднюю нагрузку, и загрузка ЦП в это время не обязательно высока. -
Большое количество запланированных процессов, ожидающих ЦП, приведет к увеличению средней нагрузки, и загрузка ЦП в это время также будет относительно высокой.
Когда средняя нагрузка высока, это может быть вызвано процессами с интенсивным использованием ЦП или загруженным вводом-выводом. Конкретный анализ можно комбинировать с инструментом mpstat/pidstat, чтобы помочь в анализе источника нагрузки.
2Процессор
Переключение контекста ЦП (вкл.)
Переключение контекста ЦП заключается в сохранении контекста ЦП (регистр ЦП и ПК) предыдущей задачи, затем загрузке контекста новой задачи в эти регистры и программный счетчик и, наконец, переходе к позиции, на которую указывает программный счетчик, для запуска новое задание. Среди них сохраненный контекст будет храниться в ядре системы и будет загружен, когда задача будет перепланирована для выполнения, чтобы гарантировать, что исходное состояние задачи не будет затронуто.
По типу задачи переключение контекста процессора делится на:
-
переключение контекста процесса -
переключение контекста потока -
переключение контекста прерывания
переключение контекста процесса
Процесс Linux делит рабочее пространство процесса на пространство ядра и пространство пользователя в соответствии с иерархическими разрешениями. Переход из пользовательского режима в режим ядра должен осуществляться через системный вызов.
Процесс системного вызова фактически выполняет два переключения контекста ЦП:
-
Позиция инструкции пользовательского режима в регистре ЦП сначала сохраняется, регистр ЦП обновляется до позиции инструкции режима ядра, и он переходит в режим ядра для запуска задачи ядра; -
После завершения системного вызова регистры ЦП восстанавливают исходные сохраненные данные пользовательского состояния, а затем переключаются в пользовательское пространство для продолжения работы.
Процесс системного вызова не использует ресурсы режима пользователя, такие как виртуальная память, и не переключает процессы. Он отличается от переключения контекста процесса в традиционном смысле. Поэтому системный вызов часто называют переключением привилегированного режима .
Процессы управляются и планируются ядром, и переключение контекста процесса может происходить только в режиме ядра. Следовательно, по сравнению с системными вызовами, перед сохранением состояния ядра и регистров ЦП текущего процесса необходимо сначала сохранить виртуальную память и стек процесса. После загрузки режима ядра нового процесса виртуальная память и пользовательский стек процесса также обновляются.
Процесс должен переключать контекст только тогда, когда он запланирован для запуска на ЦП.Существуют следующие сценарии: кванты времени ЦП выделяются по очереди, нехватка системных ресурсов приводит к зависанию процесса, активная приостановка процесса через функцию сна, и процесс с высоким приоритетом вытесняет квант времени.Когда аппаратное прерывание прерывается, процесс на ЦП приостанавливается и выполняет службу прерывания в ядре.
переключение контекста потока
Существует два типа переключения контекста потока:
-
Передний и задний потоки принадлежат одному и тому же процессу, а ресурсы виртуальной памяти при переключении остаются неизменными, переключаться нужно только приватные данные, регистры и т. д. потоков; -
Передний и задний потоки принадлежат разным процессам, что аналогично переключению контекста процесса.
Переключение потоков в одном и том же процессе потребляет меньше ресурсов, что также является преимуществом многопоточности.
переключение контекста прерывания
Переключение контекста прерывания не затрагивает пользовательский режим процесса, поэтому контекст прерывания включает только состояние, необходимое для выполнения подпрограммы обслуживания прерывания режима ядра (регистры ЦП, стек ядра, параметры аппаратного прерывания и т. д.).
Обработка прерывания имеет более высокий приоритет, чем процесс, поэтому переключение контекста прерывания и переключение контекста процесса не происходит одновременно.
Docker+K8s+Jenkins основная технология полного решения видеоданных
Переключение контекста процессора (ниже)
Вы можете просмотреть общее переключение контекста системы через vmstat
vmstat 5 #每隔5s输出一组数据
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 103388 145412 511056 0 0 18 60 1 1 2 1 96 0 0
0 0 0 103388 145412 511076 0 0 0 2 450 1176 1 1 99 0 0
0 0 0 103388 145412 511076 0 0 0 8 429 1135 1 1 98 0 0
0 0 0 103388 145412 511076 0 0 0 0 431 1132 1 1 98 0 0
0 0 0 103388 145412 511076 0 0 0 10 467 1195 1 1 98 0 0
1 0 0 103388 145412 511076 0 0 0 2 426 1139 1 0 99 0 0
4 0 0 95184 145412 511108 0 0 0 74 500 1228 4 1 94 0 0
0 0 0 103512 145416 511076 0 0 0 455 723 1573 12 3 83 2 0
-
cs (переключение контекста) количество переключений контекста в секунду -
in (interrupt) Количество прерываний в секунду -
r (runnning или runnable) длина очереди готовности, количество запущенных процессов и ожидающих CPU -
b (Blocked) Количество процессов в непрерывном спящем состоянии
Чтобы просмотреть сведения о каждом процессе, вам нужно использовать pidstat для просмотра переключения контекста каждого процесса.
pidstat -w 5
14时51分16秒 UID PID cswch/s nvcswch/s Command
14时51分21秒 0 1 0.80 0.00 systemd
14时51分21秒 0 6 1.40 0.00 ksoftirqd/0
14时51分21秒 0 9 32.67 0.00 rcu_sched
14时51分21秒 0 11 0.40 0.00 watchdog/0
14时51分21秒 0 32 0.20 0.00 khugepaged
14时51分21秒 0 271 0.20 0.00 jbd2/vda1-8
14时51分21秒 0 1332 0.20 0.00 argusagent
14时51分21秒 0 5265 10.02 0.00 AliSecGuard
14时51分21秒 0 7439 7.82 0.00 kworker/0:2
14时51分21秒 0 7906 0.20 0.00 pidstat
14时51分21秒 0 8346 0.20 0.00 sshd
14时51分21秒 0 20654 9.82 0.00 AliYunDun
14时51分21秒 0 25766 0.20 0.00 kworker/u2:1
14时51分21秒 0 28603 1.00 0.00 python3
-
cswch Произвольные переключения контекста в секунду (переключения контекста, вызванные неспособностью процесса получить требуемые ресурсы) -
nvcswch Количество непроизвольных переключений контекста в секунду (принудительное системное планирование, например чередование временных интервалов)
vmstat 1 1 #首先获取空闲系统的上下文切换次数
sysbench --threads=10 --max-time=300 threads run #模拟多线程切换问题
vmstat 1 1 #新终端观察上下文切换情况
此时发现cs数据明显升高,同时观察其他指标:
r列: 远超系统CPU个数,说明存在大量CPU竞争
us和sy列:sy列占比80%,说明CPU主要被内核占用
in列: 中断次数明显上升,说明中断处理也是潜在问题
Это означает, что слишком много процессов работает/ожидает ЦП, что приводит к большому количеству переключений контекста, а переключение контекста приводит к высокой загрузке ЦП системы.
pidstat -w -u 1 #查看到底哪个进程导致的问题
Из результатов видно, что sysbench вызывает высокую загрузку ЦП, но количество контекстов, выдаваемых pidstat, не суммируется. Анализ sysbench имитирует переключение потоков, поэтому вам нужно добавить параметр -t после pidstat, чтобы просмотреть метрики потоков.
Кроме того, при слишком большом количестве прерываний мы можем прочитать файл /proc/interrupts.
watch -d cat /proc/interrupts
Обнаружено, что самое быстрое изменение количества раз — это прерывание по перепланированию (RES), которое используется для пробуждения бездействующего ЦП для планирования запуска новых задач. Анализ по-прежнему связан с проблемой планирования слишком большого количества задач, что согласуется с анализом переключения контекста.
Что делать, если загрузка ЦП приложением достигает 100 %?
Как многозадачная операционная система, Linux делит процессорное время на очень короткие отрезки времени, которые планировщик по очереди выделяет каждой задаче. Чтобы поддерживать время процессора, Linux запускает прерывание по времени с помощью заранее определенной частоты ударов и использует глобальные паузы для записи количества ударов с момента загрузки. Прерывание по времени происходит, как только это значение +1.
Использование ЦП , время, кроме времени простоя, в процентах от общего времени ЦП. Использование ЦП можно рассчитать по данным в /proc/stat. Поскольку используется кумулятивное значение количества тиков с момента запуска /proc/stat, рассчитывается среднее использование ЦП с момента запуска, что, как правило, не имеет большого значения. Разницу между двумя значениями периода времени можно взять с интервалом для расчета средней загрузки ЦП в этот период времени. Инструмент анализа производительности показывает среднее использование ЦП за определенный период времени. Обратите внимание на настройку интервала.
Использование ЦП можно просмотреть с помощью top или ps. Проблема ЦП процесса может быть проанализирована с помощью perf, основанного на выборке событий производительности, которая может не только анализировать различные события и производительность ядра системы, но также анализировать проблемы с производительностью определенных приложений.
perf top / perf record / perf report (-g включает выборку взаимосвязей вызовов)
sudo docker run --name nginx -p 10000:80 -itd feisky/nginx
sudo docker run --name phpfpm -itd --network container:nginx feisky/php-fpm
ab -c 10 -n 100 http://XXX.XXX.XXX.XXX:10000/ #测试Nginx服务性能
Обнаружено, что количество запросов в секунду в это время может быть допустимым, и количество тестируемых запросов в это время увеличивается со 100 до 10 000. Запустите top в другом терминале, чтобы увидеть использование каждого процессора. Было обнаружено, что несколько процессов php-fpm в системе вызвали резкое увеличение загрузки ЦП.
Затем используйте perf, чтобы проанализировать, какая функция в php-fpm вызывает проблему.
perf top -g -p XXXX #对某一个php-fpm进程进行分析
Выяснилось, что sqrt и add_function занимают слишком много процессорного времени, в это время, просмотрев исходный код, оказалось, что тестовый сегмент кода в sqrt не был удален перед релизом, что вызвало миллион циклов. После удаления бесполезного кода было обнаружено, что грузоподъемность nginx значительно улучшилась
Загрузка ЦП системы очень высока, почему я не могу найти приложения с высокой загрузкой ЦП?
sudo docker run --name nginx -p 10000:80 -itd feisky/nginx:sp
sudo docker run --name phpfpm -itd --network container:nginx feisky/php-fpm:sp
ab -c 100 -n 1000 http://XXX.XXX.XXX.XXX:10000/ #并发100个请求测试
По результатам эксперимента количество запросов в секунду по-прежнему невелико, после того как мы уменьшили количество одновременных запросов до 5, грузоподъемность nginx по-прежнему остается очень низкой.
В настоящее время top и pidstat используются, чтобы обнаружить, что загрузка ЦП системы слишком высока, но процессы с высокой загрузкой ЦП не найдены.
Когда это произойдет, какой информации не хватает в нашем анализе, повторно запустите команду top и понаблюдайте некоторое время. Обнаружено, что слишком много процессов в состоянии выполнения в очереди готовности, что превышает количество одновременных запросов, которые у нас есть на 5. После тщательной проверки данных о запущенных процессах обнаруживается, что и nginx, и php-fpm находятся в состоянии состояние сна, но на самом деле запущено несколько стрессовых процессов.
Следующим шагом является использование pidstat для анализа этих стрессовых процессов и обнаружения отсутствия выходных данных. Перекрестная проверка с помощью ps aux обнаружила, что процесс по-прежнему не существует. Описание — это не вопрос инструментов. Снова проверьте верхнюю часть и обнаружите, что номер процесса стресс-процесса изменился.В настоящее время это может быть вызвано следующими двумя причинами:
-
Процесс продолжает аварийно завершать работу и перезапускаться (например, ошибка сегментации/ошибка конфигурации и т. д.), и процесс может быть перезапущен системой мониторинга после завершения процесса; -
Вызванные краткосрочными процессами, то есть внешними командами, вызываемыми другими приложениями через exec, эти команды обычно выполняются только в течение короткого времени и заканчиваются, и трудно использовать такие инструменты, как top с большими интервалами, чтобы найти
Вы можете использовать pstree, чтобы найти родительский процесс стресса и выяснить взаимосвязь вызова.
pstree | grep stress
Обнаружено, что подпроцесс, вызываемый php-fpm, является подпроцессом, вызываемым php-fpm.В настоящее время, если вы посмотрите на исходный код, вы увидите, что каждый запрос будет вызывать команду стресса для имитации давление ввода-вывода. Результат, показанный top ранее, заключается в том, что загрузка ЦП увеличилась.Необходимо дополнительно проанализировать, действительно ли это вызвано командой стресса. После добавления параметра verbose=1 к каждому запросу в коде вы можете просмотреть вывод команды stress.Результат прерывания теста команды показывает, что в сбое создания файла есть ошибка, вызванная проблемой разрешения, когда выполняется команда стресса.
На данный момент это все еще просто предположение, и следующим шагом будет продолжение его анализа с помощью инструмента perf. Отчет о производительности показывает, что стресс занимает много ресурсов ЦП, и его можно оптимизировать, устранив проблему с разрешениями.
Что делать, если в системе появилось большое количество бесперебойных процессов и процессов-зомби?
состояние процесса
-
R Running/Runnable, указывающий, что процесс находится в очереди готовности ЦП, выполняется или ожидает запуска; -
D Disk Sleep, непрерывный сон, как правило, означает, что процесс взаимодействует с оборудованием, и его нельзя прерывать другими процессами во время взаимодействия; -
Z Zombie, зомби-процесс, означает, что процесс фактически завершился, но родительский процесс не восстановил свои ресурсы; -
S Прерываемый сон, который может прервать состояние сна, что означает, что процесс приостанавливается системой, поскольку он ожидает события.Когда происходит событие ожидания, он будет пробужден и перейдет в состояние R; -
I Idle, состояние бездействия, используется для непрерываемых спящих потоков ядра. Это состояние не приведет к увеличению средней нагрузки; -
T Stop/Traced, указывающий, что процесс находится в приостановленном или отслеживаемом состоянии (SIGSTOP/SIGCONT, отладка GDB); -
X Dead, процесс мертв и не будет виден в top/ps.
Для непрерывного состояния оно обычно заканчивается за очень короткое время и может быть проигнорировано. Однако при выходе из строя системы или аппаратного обеспечения процесс может оставаться в состоянии бесперебойности в течение длительного времени, или даже в системе появляется большое количество состояний бесперебойности.В это время необходимо обратить внимание на то, существует ли Проблема производительности ввода-вывода.
Процессы-зомби обычно встречаются в многопроцессорных приложениях.Когда родительский процесс не успевает обработать состояние дочернего процесса, дочерний процесс завершается досрочно, и дочерний процесс становится процессом-зомби. У большого количества зомби-процессов закончатся номера процессов PID, что приведет к сбою установки новых процессов.
Проблема с диском O_DIRECT
sudo docker run --privileged --name=app -itd feisky/app:iowait
ps aux | grep '/app'
Видно, что в это время запущено несколько процессов приложения, а состояния — Ss+ и D+ соответственно. Последний s указывает на то, что процесс является ведущим процессом сеанса, а знак + указывает на группу процессов переднего плана.
Группа процессов представляет собой группу взаимосвязанных процессов, а дочерний процесс является членом группы, в которой находится родительский процесс. Сеанс — это группа из одного или нескольких процессов, совместно использующих один и тот же управляющий терминал.
Используйте top для просмотра системных ресурсов и обнаружите, что: 1) средняя нагрузка постепенно увеличивается, и средняя нагрузка достигает количества ЦП в течение 1 минуты, что указывает на то, что в системе может быть узкое место в производительности; 2) существует много процессов-зомби и постоянно увеличиваются; 3) Загрузка ЦП у нас и sys не высока, но iowait относительно высока; 4) Загрузка ЦП каждым процессом не высока, но два процесса находятся в состоянии D и могут ожидать ввода-вывода .
Анализ текущих данных показывает, что: iowait слишком высок, что приводит к увеличению средней нагрузки на систему, а непрерывный рост зомби-процессов указывает на то, что некоторые программы не смогли должным образом очистить ресурсы дочерних процессов.
Используйте dstat для анализа, так как он может одновременно просматривать использование ресурсов ЦП и ресурсов ввода-вывода, что удобно для сравнительного анализа.
dstat 1 10 #间隔1秒输出10组数据
Видно, что при увеличении wai (iowait) запрос на чтение с диска будет очень большим, что указывает на то, что увеличение iowait связано с запросом на чтение с диска. Затем проанализируйте, какой процесс читает диск в данный момент.
Номер процесса в состоянии D, который ранее был просмотрен top, используйте pidstat -d -p XXX, чтобы отобразить статистику ввода-вывода процесса. Обнаружено, что ни один из процессов в состоянии D не имеет операций чтения и записи. Используйте pidstat -d для просмотра статистики ввода-вывода всех процессов и убедитесь, что процесс приложения выполняет операции чтения с диска, считывая 32 МБ данных в секунду. Процесс должен использовать системный вызов для доступа к диску в состоянии ядра.Следующий момент — найти системный вызов процесса приложения.
sudo strace -p XXX #对app进程调用进行跟踪
Нет разрешения сообщать об ошибке, потому что она уже укоренена. Итак, в этом случае первое, что нужно проверить, это нормальное состояние процесса. Команда ps обнаруживает, что процесс уже находится в состоянии Z, то есть процесс-зомби.
В этом случае такие инструменты, как top pidstat, не могут дать больше информации.В настоящее время, как и в части 5, используйте perf record -d и perf report для анализа и просмотра стека вызовов процесса приложения.
Видно, что приложение действительно считывает данные через системный вызов sys_read(), а когда процесс виден из new_sync_read и blkdev_direct_IO, выполняется операция прямого чтения, запрос читается прямо с диска, а iowait не увеличено через кеш.
После послойного анализа основной причиной является прямой ввод-вывод диска внутри приложения. Затем найдите конкретную позицию кода для оптимизации.
процесс зомби
После вышеописанной оптимизации iowait значительно падает, но количество процессов-зомби все равно увеличивается. Сначала найдите родительский процесс зомби-процесса, распечатайте дерево вызовов зомби-процесса с помощью pstree -aps XXX и обнаружите, что родительский процесс — это процесс приложения.
Проверьте код приложения, чтобы увидеть, правильно ли обрабатывается конец дочернего процесса (вызывается ли wait()/waitpid(), есть ли обработчик для регистрации сигнала SIGCHILD и т. д.).
Когда iowait повышается, сначала используйте такие инструменты, как dstat и pidstat, чтобы подтвердить, есть ли проблема дискового ввода-вывода, а затем выясните, какие процессы вызывают ввод-вывод.Если вы не можете использовать strace для прямого анализа вызова процесса, вы можно использовать инструмент perf для его анализа.
Для решения проблемы зомби используйте pstree, чтобы найти родительский процесс, а затем просмотрите исходный код, чтобы проверить логику обработки для завершения дочернего процесса.
Показатели производительности процессора
-
использование процессора
-
Использование процессора пользователем, включая пользовательский режим (user) и низкоприоритетный пользовательский режим (nice).Если этот показатель слишком высок, приложение занято. -
Использование ЦП системы, процент времени, в течение которого ЦП работает в режиме ядра (исключая прерывания).Высокий показатель указывает на то, что ядро занято. -
Загрузка ЦП в ожидании ввода-вывода, iowait, высокое значение этого индикатора указывает на то, что системе требуется много времени для взаимодействия с аппаратным вводом-выводом устройства. -
Мягкое/жесткое прерывание Загрузка ЦП, высокий индикатор указывает на большое количество прерываний в системе. -
украсть ЦП / гостевой ЦП, который указывает процент ЦП, занятый виртуальной машиной. -
средняя нагрузка
В идеале средняя нагрузка равна количеству логических ЦП, что указывает на то, что каждый ЦП загружен полностью.Если она больше, это означает, что система находится под большой нагрузкой.
-
переключение контекста процесса
Включая добровольное переключение, когда ресурсы не могут быть получены, и принудительное переключение, когда система вынуждена планировать.Переключение контекста само по себе является основной функцией, обеспечивающей нормальную работу Linux.Чрезмерное переключение потребляет время ЦП исходного запущенного процесса в регистрах, и ядро занимает и виртуальную память и другое сохранение и восстановление данных
-
Коэффициент попаданий в кэш процессора
Для повторного использования кеша ЦП, чем выше частота попаданий, тем лучше производительность.Среди них L1/L2 обычно используется в одноядерных, а L3 используется в многоядерных
инструменты производительности
-
Случай средней нагрузки -
Сначала используйте время безотказной работы, чтобы проверить среднюю загрузку системы. -
Убедившись, что нагрузка увеличилась, используйте mpstat и pidstat, чтобы просмотреть загрузку ЦП каждого ЦП и каждого процесса соответственно.Выясните, какой процесс вызывает более высокую среднюю нагрузку. -
случай переключения контекста -
Сначала используйте vmstat для просмотра количества переключений системного контекста и прерываний. -
Затем используйте pidstat для наблюдения за произвольным и непроизвольным переключением контекста процесса. -
Наконец, наблюдайте за переключением контекста потока через pidstat. -
Высокая загрузка ЦП в случае процесса -
Сначала используйте top, чтобы просмотреть использование ЦП системой и процессом, а также найти процесс. -
Затем используйте perf top, чтобы наблюдать за цепочкой вызовов процесса и найти конкретную функцию. -
Случаи с высокой загрузкой ЦП системы -
Сначала используйте top, чтобы проверить загрузку ЦП системой и процессом, top/pidstat не может найти процесс с высокой загрузкой ЦП. -
Вернуться к выходу -
Начните с процессов, которые имеют низкую загрузку ЦП, но находятся в состоянии «Выполняется». -
Запись/отчет Perf находит краткосрочные причины процесса (инструмент execsnoop) -
Кейсы бесперебойного и зомби-процесса -
Сначала используйте top, чтобы понаблюдать за ростом iowait и найти большое количество непрерываемых и зомби-процессов. -
strace не может отслеживать системные вызовы процесса -
Perf анализирует цепочку вызовов и обнаруживает, что основной причиной является прямой дисковый ввод-вывод. -
Случай мягкого прерывания -
Top отмечает, что системное программное прерывание использует ЦП высоко. -
Проверьте /proc/softirqs, чтобы найти несколько программных прерываний с более высокой скоростью изменения. -
Команда sar обнаружила, что проблема связана с сетевыми пакетами. -
tcpdump выясняет тип и источник сетевого фрейма, а также определяет причину атаки SYN FLOOD
Найдите подходящий инструмент на основе различных показателей эффективности:
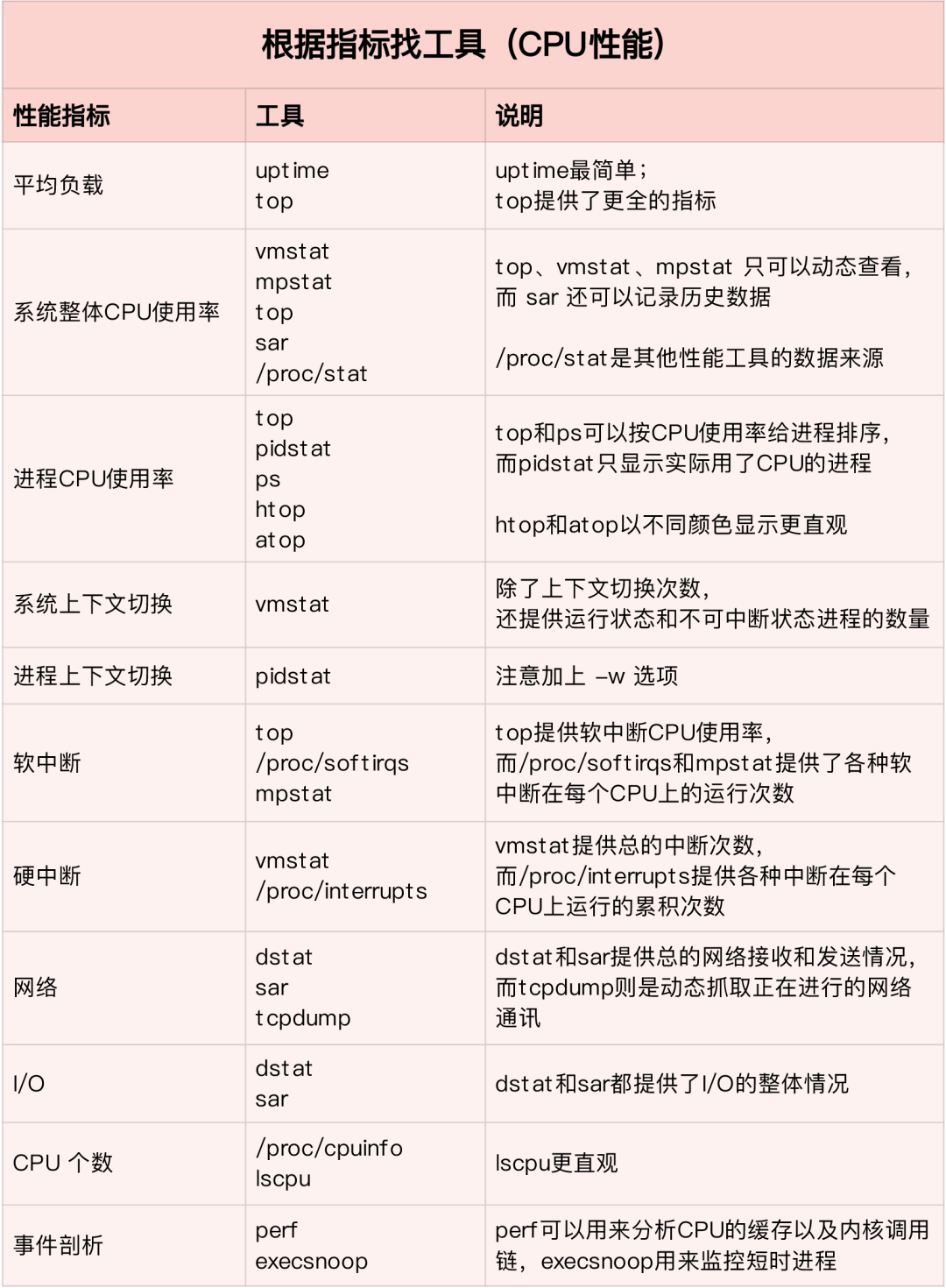
В производственной среде разработчики часто не имеют разрешения на установку новых инструментов, и могут только максимально использовать инструменты, уже установленные в системе, поэтому необходимо понимать, анализ какого показателя могут предоставить некоторые основные инструменты.
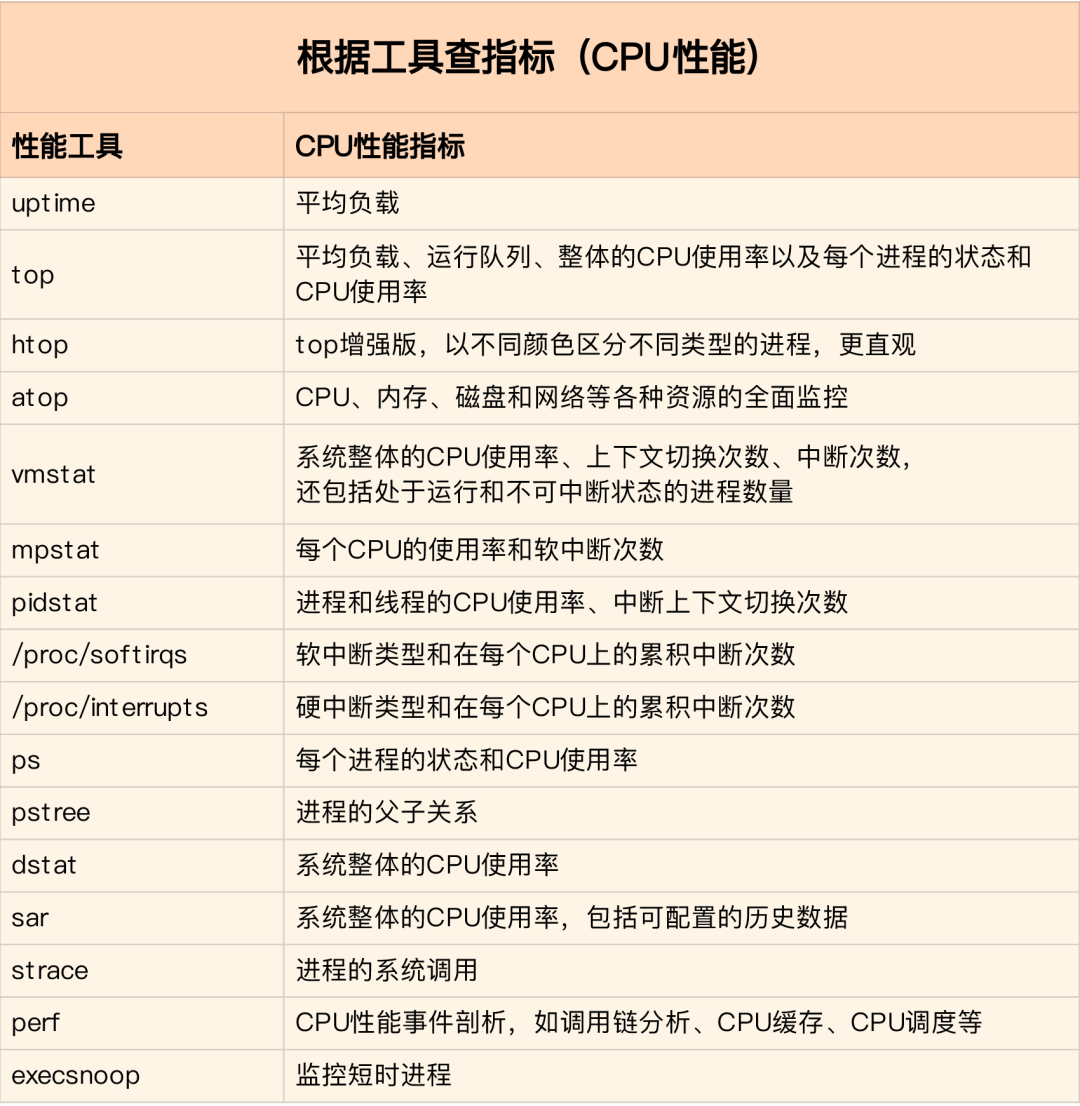
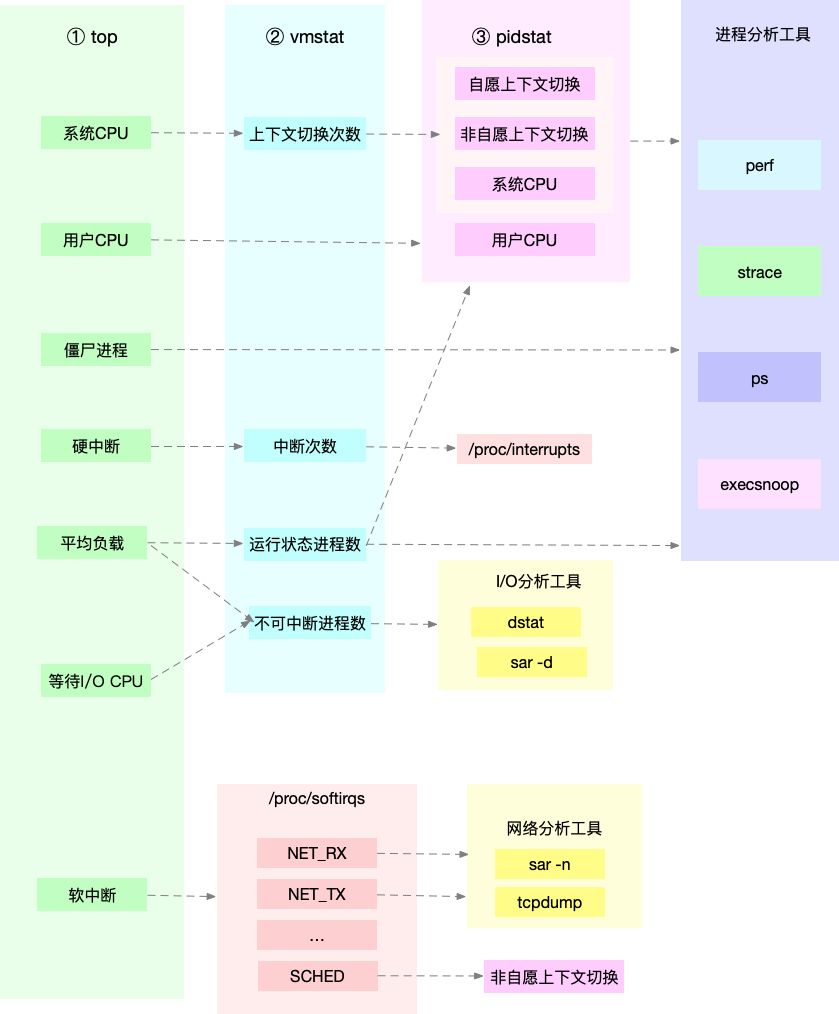
Сначала запустите несколько инструментов, которые поддерживают больше индикаторов, таких как top/vmstat/pidstat, в зависимости от их выходных данных вы можете узнать, к какому типу относится проблема производительности.После обнаружения процесса используйте strace/perf для анализа ситуации вызова для дальнейшего Если да, Softirqs приводит к /proc/softirqs
оптимизация ЦП
-
Оптимизация приложений
-
Оптимизация компилятора: включите параметры оптимизации во время компиляции, например, gcc -O2. -
Оптимизация алгоритма -
Асинхронная обработка: предотвратите блокировку программы из-за ожидания ресурса и улучшите возможности одновременной обработки программы (замените опрос уведомлением о событии). -
Многопоточность вместо многопроцессорности: снижение затрат на переключение контекста -
Эффективно используйте кеш: ускорьте обработку программы -
Оптимизация системы
-
Привязка ЦП: привяжите процесс к 1/нескольким ЦП, улучшите частоту попаданий в кэш ЦП и уменьшите переключение контекста, вызванное планированием ЦП. -
Эксклюзивно для ЦП: механизм привязки ЦП для распределения процессов. -
Настройка приоритета: используйте nice, чтобы соответствующим образом снизить приоритет неосновных приложений. -
Установите отображение ресурсов для процесса: контрольные группы устанавливают верхний предел, чтобы предотвратить истощение системных ресурсов из-за собственных проблем приложения. -
Оптимизация NUMA: ЦП максимально использует локальную память. -
Балансировка нагрузки прерываний: irpbalance, которая автоматически балансирует нагрузку процесса обработки прерывания для каждого процессора. -
Разница и понимание TPS, QPS и пропускной способности системы
-
Число запросов в секунду (TPS)
-
параллелизм
-
Время отклика
QPS (TPS) = количество одновременных запросов / среднее время ответа
-
Сервер запросов пользователей
-
Внутренняя обработка сервера
-
Сервер возвращается к клиенту
QPS похож на TPS, но доступ к странице формирует TPS, но запрос страницы может содержать несколько запросов к серверу, которые могут считаться несколькими QPS.
-
QPS (Queries Per Second) частота запросов в секунду, количество запросов, на которые сервер может ответить в секунду.
-
TPS (Transactions Per Second) Количество транзакций в секунду, результат тестирования ПО.
-
Пропускная способность системы, включая несколько важных параметров:
3Память
Linux内存是怎么工作的
内存映射
大多数计算机用的主存都是动态随机访问内存(DRAM),只有内核才可以直接访问物理内存。Linux内核给每个进程提供了一个独立的虚拟地址空间,并且这个地址空间是连续的。这样进程就可以很方便的访问内存(虚拟内存)。
虚拟地址空间的内部分为内核空间和用户空间两部分,不同字长的处理器地址空间的范围不同。32位系统内核空间占用1G,用户空间占3G。64位系统内核空间和用户空间都是128T,分别占内存空间的最高和最低处,中间部分为未定义。
并不是所有的虚拟内存都会分配物理内存,只有实际使用的才会。分配后的物理内存通过内存映射管理。为了完成内存映射,内核为每个进程都维护了一个页表,记录虚拟地址和物理地址的映射关系。页表实际存储在CPU的内存管理单元MMU中,处理器可以直接通过硬件找出要访问的内存。
当进程访问的虚拟地址在页表中查不到时,系统会产生一个缺页异常,进入内核空间分配物理内存,更新进程页表,再返回用户空间恢复进程的运行。
MMU以页为单位管理内存,页大小4KB。为了解决页表项过多问题Linux提供了多级页表和HugePage的机制。
虚拟内存空间分布
用户空间内存从低到高是五种不同的内存段:
-
只读段 代码和常量等 -
数据段 全局变量等 -
堆 动态分配的内存,从低地址开始向上增长 -
文件映射 动态库、共享内存等,从高地址开始向下增长 -
栈 包括局部变量和函数调用的上下文等,栈的大小是固定的。一般8MB
内存分配与回收
分配
malloc对应到系统调用上有两种实现方式:
-
brk() 针对小块内存(<128K),通过移动堆顶位置来分配。内存释放后不立即归还内存,而是被缓存起来。 -
**mmap()**针对大块内存(>128K),直接用内存映射来分配,即在文件映射段找一块空闲内存分配。
前者的缓存可以减少缺页异常的发生,提高内存访问效率。但是由于内存没有归还系统,在内存工作繁忙时,频繁的内存分配/释放会造成内存碎片。
后者在释放时直接归还系统,所以每次mmap都会发生缺页异常。在内存工作繁忙时,频繁内存分配会导致大量缺页异常,使内核管理负担增加。
上述两种调用并没有真正分配内存,这些内存只有在首次访问时,才通过缺页异常进入内核中,由内核来分配
回收
内存紧张时,系统通过以下方式来回收内存:
-
回收缓存:LRU算法回收最近最少使用的内存页面;
-
回收不常访问内存:把不常用的内存通过交换分区写入磁盘
-
杀死进程:OOM内核保护机制 (进程消耗内存越大oom_score越大,占用CPU越多oom_score越小,可以通过/proc手动调整oom_adj)
echo -16 > /proc/$(pidof XXX)/oom_adj
如何查看内存使用情况
free来查看整个系统的内存使用情况
top/ps来查看某个进程的内存使用情况
-
VIRT 进程的虚拟内存大小 -
RES 常驻内存的大小,即进程实际使用的物理内存大小,不包括swap和共享内存 -
SHR 共享内存大小,与其他进程共享的内存,加载的动态链接库以及程序代码段 -
%MEM 进程使用物理内存占系统总内存的百分比
怎样理解内存中的Buffer和Cache?
buffer是对磁盘数据的缓存,cache是对文件数据的缓存,它们既会用在读请求也会用在写请求中
如何利用系统缓存优化程序的运行效率
缓存命中率
缓存命中率是指直接通过缓存获取数据的请求次数,占所有请求次数的百分比。命中率越高说明缓存带来的收益越高,应用程序的性能也就越好。
安装bcc包后可以通过cachestat和cachetop来监测缓存的读写命中情况。
安装pcstat后可以查看文件在内存中的缓存大小以及缓存比例
#首先安装Go
export GOPATH=~/go
export PATH=~/go/bin:$PATH
go get golang.org/x/sys/unix
go ge github.com/tobert/pcstat/pcstat
dd缓存加速
dd if=/dev/sda1 of=file bs=1M count=512 #生产一个512MB的临时文件
echo 3 > /proc/sys/vm/drop_caches #清理缓存
pcstat file #确定刚才生成文件不在系统缓存中,此时cached和percent都是0
cachetop 5
dd if=file of=/dev/null bs=1M #测试文件读取速度
#此时文件读取性能为30+MB/s,查看cachetop结果发现并不是所有的读都落在磁盘上,读缓存命中率只有50%。
dd if=file of=/dev/null bs=1M #重复上述读文件测试
#此时文件读取性能为4+GB/s,读缓存命中率为100%
pcstat file #查看文件file的缓存情况,100%全部缓存
O_DIRECT选项绕过系统缓存
cachetop 5
sudo docker run --privileged --name=app -itd feisky/app:io-direct
sudo docker logs app #确认案例启动成功
#实验结果表明每读32MB数据都要花0.9s,且cachetop输出中显示1024次缓存全部命中
但是凭感觉可知如果缓存命中读速度不应如此慢,读次数时1024,页大小为4K,五秒的时间内读取了1024*4KB数据,即每秒0.8MB,和结果中32MB相差较大。说明该案例没有充分利用缓存,怀疑系统调用设置了直接I/O标志绕过系统缓存。因此接下来观察系统调用.
strace -p $(pgrep app)
#strace 结果可以看到openat打开磁盘分区/dev/sdb1,传入参数为O_RDONLY|O_DIRECT
这就解释了为什么读32MB数据那么慢,直接从磁盘读写肯定远远慢于缓存。找出问题后我们再看案例的源代码发现flags中指定了直接IO标志。删除该选项后重跑,验证性能变化。
内存泄漏,如何定位和处理?
对应用程序来说,动态内存的分配和回收是核心又复杂的一个逻辑功能模块。管理内存的过程中会发生各种各样的“事故”:
-
没正确回收分配的内存,导致了泄漏 -
访问的是已分配内存边界外的地址,导致程序异常退出
内存的分配与回收
虚拟内存分布从低到高分别是只读段,数据段,堆,内存映射段,栈五部分。其中会导致内存泄漏的是:
-
堆:由应用程序自己来分配和管理,除非程序退出这些堆内存不会被系统自动释放。 -
内存映射段:包括动态链接库和共享内存,其中共享内存由程序自动分配和管理
内存泄漏的危害比较大,这些忘记释放的内存,不仅应用程序自己不能访问,系统也不能把它们再次分配给其他应用。 内存泄漏不断累积甚至会耗尽系统内存.
如何检测内存泄漏
预先安装systat,docker,bcc
sudo docker run --name=app -itd feisky/app:mem-leak
sudo docker logs app
vmstat 3
可以看到free在不断下降,buffer和cache基本保持不变。说明系统的内存一致在升高。但并不能说明存在内存泄漏。此时可以通过memleak工具来跟踪系统或进程的内存分配/释放请求
/usr/share/bcc/tools/memleak -a -p $(pidof app)
从memleak输出可以看到,应用在不停地分配内存,并且这些分配的地址并没有被回收。通过调用栈看到是fibonacci函数分配的内存没有释放。定位到源码后查看源码来修复增加内存释放函数即可.
为什么系统的Swap变高
系统内存资源紧张时通过内存回收和OOM杀死进程来解决。其中可回收内存包括:
-
缓存/缓冲区,属于可回收资源,在文件管理中通常叫做文件页 -
在应用程序中通过fsync将脏页同步到磁盘 -
交给系统,内核线程pdflush负责这些脏页的刷新 -
被应用程序修改过暂时没写入磁盘的数据(脏页),要先写入磁盘然后才能内存释放 -
内存映射获取的文件映射页,也可以被释放掉,下次访问时从文件重新读取
对于程序自动分配的堆内存,也就是我们在内存管理中的匿名页,虽然这些内存不能直接释放,但是Linux提供了Swap机制将不常访问的内存写入到磁盘来释放内存,再次访问时从磁盘读取到内存即可。
Swap原理
Swap本质就是把一块磁盘空间或者一个本地文件当作内存来使用,包括换入和换出两个过程:
-
换出:将进程暂时不用的内存数据存储到磁盘中,并释放这些内存 -
换入:进程再次访问内存时,将它们从磁盘读到内存中
Linux如何衡量内存资源是否紧张?
-
直接内存回收 新的大块内存分配请求,但剩余内存不足。此时系统会回收一部分内存;
-
kswapd0 内核线程定期回收内存。为了衡量内存使用情况,定义了pages_min,pages_low,pages_high三个阈值,并根据其来进行内存的回收操作。
-
剩余内存 < pages_min,进程可用内存耗尽了,只有内核才可以分配内存
-
pages_min < 剩余内存 < pages_low,内存压力较大,kswapd0执行内存回收,直到剩余内存 > pages_high
-
pages_low < 剩余内存 < pages_high,内存有一定压力,但可以满足新内存请求
-
剩余内存 > pages_high,说明剩余内存较多,无内存压力
pages_low = pages_min 5 / 4 pages_high = pages_min 3 / 2
NUMA 与 SWAP
很多情况下系统剩余内存较多,但SWAP依旧升高,这是由于处理器的NUMA架构。
在NUMA架构下多个处理器划分到不同的Node,每个Node都拥有自己的本地内存空间。在分析内存的使用时应该针对每个Node单独分析
numactl --hardware #查看处理器在Node的分布情况,以及每个Node的内存使用情况
内存三个阈值可以通过/proc/zoneinfo来查看,该文件中还包括活跃和非活跃的匿名页/文件页数。
当某个Node内存不足时,系统可以从其他Node寻找空闲资源,也可以从本地内存中回收内存。通过/proc/sys/vm/zone_raclaim_mode来调整。
-
0表示既可以从其他Node寻找空闲资源,也可以从本地回收内存 -
1,2,4表示只回收本地内存,2表示可以会回脏数据回收内存,4表示可以用Swap方式回收内存。
swappiness
在实际回收过程中Linux根据/proc/sys/vm/swapiness选项来调整使用Swap的积极程度,从0-100,数值越大越积极使用Swap,即更倾向于回收匿名页;数值越小越消极使用Swap,即更倾向于回收文件页。
注意:这只是调整Swap积极程度的权重,即使设置为0,当剩余内存+文件页小于页高阈值时,还是会发生Swap。
Swap升高时如何定位分析
free #首先通过free查看swap使用情况,若swap=0表示未配置Swap
#先创建并开启swap
fallocate -l 8G /mnt/swapfile
chmod 600 /mnt/swapfile
mkswap /mnt/swapfile
swapon /mnt/swapfile
free #再次执行free确保Swap配置成功
dd if=/dev/sda1 of=/dev/null bs=1G count=2048 #模拟大文件读取
sar -r -S 1 #查看内存各个指标变化 -r内存 -S swap
#根据结果可以看出,%memused在不断增长,剩余内存kbmemfress不断减少,缓冲区kbbuffers不断增大,由此可知剩余内存不断分配给了缓冲区
#一段时间之后,剩余内存很小,而缓冲区占用了大部分内存。此时Swap使用之间增大,缓冲区和剩余内存只在小范围波动
停下sar命令
cachetop5 #观察缓存
#可以看到dd进程读写只有50%的命中率,未命中数为4w+页,说明正式dd进程导致缓冲区使用升高
watch -d grep -A 15 ‘Normal’ /proc/zoneinfo #观察内存指标变化
#发现升级内存在一个小范围不停的波动,低于页低阈值时会突然增大到一个大于页高阈值的值
说明剩余内存和缓冲区的波动变化正是由于内存回收和缓存再次分配的循环往复。有时候Swap用的多,有时候缓冲区波动更多。此时查看swappiness值为60,是一个相对中和的配置,系统会根据实际运行情况来选去合适的回收类型.
如何“快准狠”找到系统内存存在的问题
内存性能指标
系统内存指标
-
已用内存/剩余内存 -
共享内存 (tmpfs实现) -
可用内存:包括剩余内存和可回收内存 -
缓存:磁盘读取文件的页缓存,slab分配器中的可回收部分 -
缓冲区:原始磁盘块的临时存储,缓存将要写入磁盘的数据
进程内存指标
-
虚拟内存:5大部分 -
常驻内存:进程实际使用的物理内存,不包括Swap和共享内存 -
共享内存:与其他进程共享的内存,以及动态链接库和程序的代码段 -
Swap内存:通过Swap换出到磁盘的内存
缺页异常
-
可以直接从物理内存中分配,次缺页异常 -
需要磁盘IO介入(如Swap),主缺页异常。此时内存访问会慢很多
内存性能工具
根据不同的性能指标来找合适的工具:
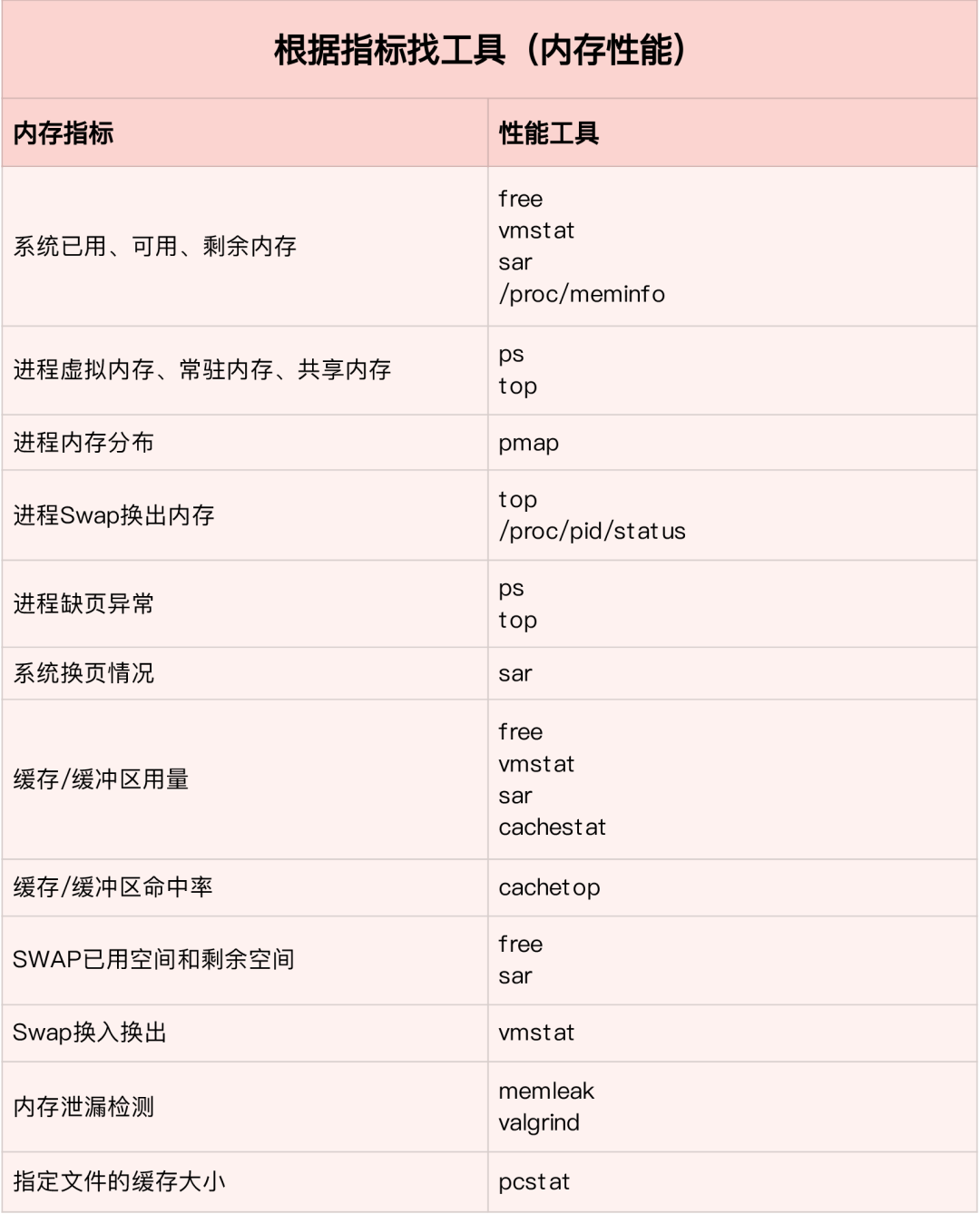
内存分析工具包含的性能指标:
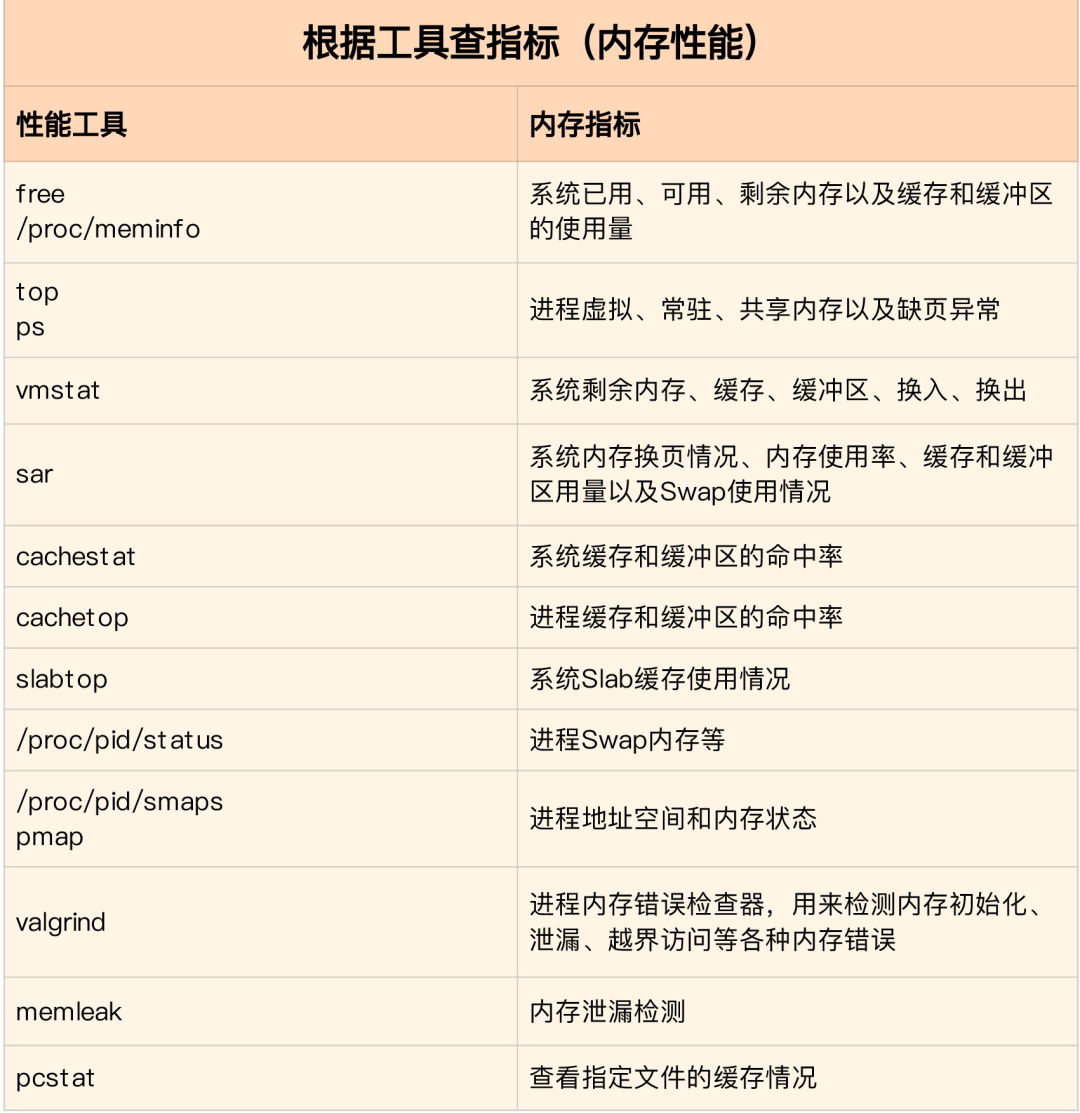
如何迅速分析内存的性能瓶颈
通常先运行几个覆盖面比较大的性能工具,如free,top,vmstat,pidstat等
-
先用free和top查看系统整体内存使用情况 -
再用vmstat和pidstat,查看一段时间的趋势,从而判断内存问题的类型 -
最后进行详细分析,比如内存分配分析,缓存/缓冲区分析,具体进程的内存使用分析等
常见的优化思路:
-
最好禁止Swap,若必须开启则尽量降低swappiness的值 -
减少内存的动态分配,如可以用内存池,HugePage等 -
尽量使用缓存和缓冲区来访问数据。如用堆栈明确声明内存空间来存储需要缓存的数据,或者用Redis外部缓存组件来优化数据的访问 -
cgroups等方式来限制进程的内存使用情况,确保系统内存不被异常进程耗尽 -
/proc/pid/oom_adj调整核心应用的oom_score,保证即使内存紧张核心应用也不会被OOM杀死
vmstat使用详解
vmstat命令是最常见的Linux/Unix监控工具,可以展现给定时间间隔的服务器的状态值,包括服务器的CPU使用率,内存使用,虚拟内存交换情况,IO读写情况。可以看到整个机器的CPU,内存,IO的使用情况,而不是单单看到各个进程的CPU使用率和内存使用率(使用场景不一样)。
vmstat 2
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 1379064 282244 11537528 0 0 3 104 0 0 3 0 97 0 0
0 0 0 1372716 282244 11537544 0 0 0 24 4893 8947 1 0 98 0 0
0 0 0 1373404 282248 11537544 0 0 0 96 5105 9278 2 0 98 0 0
0 0 0 1374168 282248 11537556 0 0 0 0 5001 9208 1 0 99 0 0
0 0 0 1376948 282248 11537564 0 0 0 80 5176 9388 2 0 98 0 0
0 0 0 1379356 282256 11537580 0 0 0 202 5474 9519 2 0 98 0 0
1 0 0 1368376 282256 11543696 0 0 0 0 5894 8940 12 0 88 0 0
1 0 0 1371936 282256 11539240 0 0 0 10554 6176 9481 14 1 85 1 0
1 0 0 1366184 282260 11542292 0 0 0 7456 6102 9983 7 1 91 0 0
1 0 0 1353040 282260 11556176 0 0 0 16924 7233 9578 18 1 80 1 0
0 0 0 1359432 282260 11549124 0 0 0 12576 5495 9271 7 0 92 1 0
0 0 0 1361744 282264 11549132 0 0 0 58 8606 15079 4 2 95 0 0
1 0 0 1367120 282264 11549140 0 0 0 2 5716 9205 8 0 92 0 0
0 0 0 1346580 282264 11562644 0 0 0 70 6416 9944 12 0 88 0 0
0 0 0 1359164 282264 11550108 0 0 0 2922 4941 8969 3 0 97 0 0
1 0 0 1353992 282264 11557044 0 0 0 0 6023 8917 15 0 84 0 0
# 结果说明
- r 表示运行队列(就是说多少个进程真的分配到CPU),我测试的服务器目前CPU比较空闲,没什么程序在跑,当这个值超过了CPU数目,就会出现CPU瓶颈了。这个也和top的负载有关系,一般负载超过了3就比较高,超过了5就高,超过了10就不正常了,服务器的状态很危险。top的负载类似每秒的运行队列。如果运行队列过大,表示你的CPU很繁忙,一般会造成CPU使用率很高。
- b 表示阻塞的进程,这个不多说,进程阻塞,大家懂的。
- swpd 虚拟内存已使用的大小,如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。
- free 空闲的物理内存的大小,我的机器内存总共8G,剩余3415M。
- buff Linux/Unix系统是用来存储,目录里面有什么内容,权限等的缓存,我本机大概占用300多M
- cache cache直接用来记忆我们打开的文件,给文件做缓冲,我本机大概占用300多M(这里是Linux/Unix的聪明之处,把空闲的物理内存的一部分拿来做文件和目录的缓存,是为了提高 程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用。)
- si 每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。我的机器内存充裕,一切正常。
- so 每秒虚拟内存写入磁盘的大小,如果这个值大于0,同上。
- bi 块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024byte,我本机上没什么IO操作,所以一直是0,但是我曾在处理拷贝大量数据(2-3T)的机器上看过可以达到140000/s,磁盘写入速度差不多140M每秒
- bo 块设备每秒发送的块数量,例如我们读取文件,bo就要大于0。bi和bo一般都要接近0,不然就是IO过于频繁,需要调整。
- in 每秒CPU的中断次数,包括时间中断
- cs 每秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。
- us 用户CPU时间,我曾经在一个做加密解密很频繁的服务器上,可以看到us接近100,r运行队列达到80(机器在做压力测试,性能表现不佳)。
- sy 系统CPU时间,如果太高,表示系统调用时间长,例如是IO操作频繁。
- id 空闲CPU时间,一般来说,id + us + sy = 100,一般我认为id是空闲CPU使用率,us是用户CPU使用率,sy是系统CPU使用率。
- wt 等待IO CPU时间
pidstat 使用详解
pidstat主要用于监控全部或指定进程占用系统资源的情况,如CPU,内存、设备IO、任务切换、线程等。
使用方法:
-
pidstat –d interval times 统计各个进程的IO使用情况 -
pidstat –u interval times 统计各个进程的CPU统计信息 -
pidstat –r interval times 统计各个进程的内存使用信息 -
pidstat -w interval times 统计各个进程的上下文切换 -
p PID 指定PID
1、统计IO使用情况
pidstat -d 1 10
03:02:02 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s Command
03:02:03 PM 0 816 0.00 918.81 0.00 jbd2/vda1-8
03:02:03 PM 0 1007 0.00 3.96 0.00 AliYunDun
03:02:03 PM 997 7326 0.00 1904.95 918.81 java
03:02:03 PM 997 8539 0.00 3.96 0.00 java
03:02:03 PM 0 16066 0.00 35.64 0.00 cmagent
03:02:03 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s Command
03:02:04 PM 0 816 0.00 1924.00 0.00 jbd2/vda1-8
03:02:04 PM 997 7326 0.00 11156.00 1888.00 java
03:02:04 PM 997 8539 0.00 4.00 0.00 java
-
UID -
PID -
kB_rd/s: 每秒进程从磁盘读取的数据量 KB 单位 read from disk each second KB -
kB_wr/s: 每秒进程向磁盘写的数据量 KB 单位 write to disk each second KB -
kB_ccwr/s: 每秒进程向磁盘写入,但是被取消的数据量,This may occur when the task truncates some dirty pagecache. -
iodelay: Block I/O delay, measured in clock ticks -
Command: 进程名 task name
2、统计CPU使用情况
# 统计CPU
pidstat -u 1 10
03:03:33 PM UID PID %usr %system %guest %CPU CPU Command
03:03:34 PM 0 2321 3.96 0.00 0.00 3.96 0 ansible
03:03:34 PM 0 7110 0.00 0.99 0.00 0.99 4 pidstat
03:03:34 PM 997 8539 0.99 0.00 0.00 0.99 5 java
03:03:34 PM 984 15517 0.99 0.00 0.00 0.99 5 java
03:03:34 PM 0 24406 0.99 0.00 0.00 0.99 5 java
03:03:34 PM 0 32158 3.96 0.00 0.00 3.96 2 ansible
-
UID -
PID -
%usr: 进程在用户空间占用 cpu 的百分比 -
%system: 进程在内核空间占用 CPU 百分比 -
%guest: 进程在虚拟机占用 CPU 百分比 -
%wait: 进程等待运行的百分比 -
%CPU: 进程占用 CPU 百分比 -
CPU: 处理进程的 CPU 编号 -
Command: 进程名
3、统计内存使用情况
# 统计内存
pidstat -r 1 10
Average: UID PID minflt/s majflt/s VSZ RSS %MEM Command
Average: 0 1 0.20 0.00 191256 3064 0.01 systemd
Average: 0 1007 1.30 0.00 143256 22720 0.07 AliYunDun
Average: 0 6642 0.10 0.00 6301904 107680 0.33 java
Average: 997 7326 10.89 0.00 13468904 8395848 26.04 java
Average: 0 7795 348.15 0.00 108376 1233 0.00 pidstat
Average: 997 8539 0.50 0.00 8242256 2062228 6.40 java
Average: 987 9518 0.20 0.00 6300944 1242924 3.85 java
Average: 0 10280 3.70 0.00 807372 8344 0.03 aliyun-service
Average: 984 15517 0.40 0.00 6386464 1464572 4.54 java
Average: 0 16066 236.46 0.00 2678332 71020 0.22 cmagent
Average: 995 20955 0.30 0.00 6312520 1408040 4.37 java
Average: 995 20956 0.20 0.00 6093764 1505028 4.67 java
Average: 0 23936 0.10 0.00 5302416 110804 0.34 java
Average: 0 24406 0.70 0.00 10211672 2361304 7.32 java
Average: 0 26870 1.40 0.00 1470212 36084 0.11 promtail
-
UID -
PID -
Minflt/s : количество ошибок страниц в секунду (незначительные ошибки страниц), количество ошибок страниц, сгенерированных путем сопоставления адресов виртуальной памяти с адресами физической памяти. -
Majflt/s : количество ошибок основных страниц в секунду (основных ошибок страниц), когда адрес виртуальной памяти сопоставляется с адресом физической памяти, соответствующая страница находится в свопе. -
Использование виртуальной памяти VSZ: единица КБ виртуальной памяти, используемая процессом. -
RSS: физическая память, используемая процессом в КБ. -
%MEM: использование памяти -
Command : имя командной задачи процесса
4. Просмотр использования определенных процессов
pidstat -T ALL -r -p 20955 1 10
03:12:16 PM UID PID minflt/s majflt/s VSZ RSS %MEM Command
03:12:17 PM 995 20955 0.00 0.00 6312520 1408040 4.37 java
03:12:16 PM UID PID minflt-nr majflt-nr Command
03:12:17 PM 995 20955 0 0 javaКОНЕЦ
Официальный сайт: www.linuxprobe.com
Энциклопедия команд Linux: www.linuxcool.com

Учитель Лю Трент QQ: 5604241
Группа технического обмена Linux: 3586725
(Новая группа, в горячей группе...)
Читатели, которые хотят изучить систему Linux, могут нажать кнопку «Прочитать исходный текст» , чтобы узнать о книге «Linux следует изучать так». -ценный справочник для помощи в работе!