В крупномасштабной микросервисной архитектуре для мониторинга и анализа сервисов в реальном времени требуются большие объемы данных временных рядов. Наиболее эффективным способом хранения данных временных рядов является использование базы данных временных рядов (TSDB). Одной из важных задач при проектировании баз данных временных рядов является поиск баланса между эффективностью, масштабируемостью и надежностью. В этой статье представлена оперативная база данных временных рядов Gorilla, разработанная в Facebook. Команда Facebook обнаружила:
-
Пользователи систем эпиднадзора в первую очередь заинтересованы в агрегированном анализе данных, а не в отдельных точках данных. -
Недавние данные более ценны, чем прошлые данные для анализа первопричин онлайн-проблем.
Gorilla оптимизирована для обеспечения высокой доступности при чтении и записи за счет потенциальной потери небольшого объема данных. Чтобы повысить эффективность запросов, команда разработчиков использовала агрессивные методы сжатия:
-
временные метки дельта-дельта -
XOR-значения с плавающей запятой
По сравнению с решениями на основе HBase, Gorilla в 10 раз снижает потребление памяти и позволяет хранить данные в памяти, тем самым уменьшая задержку запросов в 73 раза и увеличивая пропускную способность запросов в 14 раз. Такие улучшения производительности также открывают дополнительные инструменты мониторинга и отладки, такие как корреляционный анализ, интенсивная визуализация. Gorilla может даже корректно разрешать отказы одной точки во всей зоне доступности.
вводить
Ниже приведены внутренние требования ФБ к базе данных временных рядов:
Написать Доминировать
Первое ограничение для баз данных временных рядов заключается в том, что данные должны иметь возможность записи все время, то есть высокая доступность данных для записи. Потому что сервисный кластер внутри FB будет генерировать 10 миллионов выборочных точек данных в секунду. Напротив, чтение данных обычно на несколько порядков ниже, чем запись данных, потому что потребителями данных являются некоторые панели управления для эксплуатации и обслуживания, разработки и использования, а также автоматические системы сигнализации, которые имеют низкую частоту запросов и обычно фокусируются только на части. данных временного ряда. Поскольку пользователей часто интересуют агрегированные результаты всего набора данных временных рядов, а не одной точки данных, гарантии ACID в традиционных базах данных не являются основными требованиями к базам данных временных рядов. данные не повлияют на ядро.использование.
Государственный переход
FB надеется вовремя обнаружить некоторые события перехода состояния системы, такие как:
-
Вышла новая версия сервиса -
Изменение конфигурации службы -
Сетевой коммутатор -
...
Следовательно, база данных временных рядов должна поддерживать мелкозернистую агрегацию выборочных данных в течение короткого промежутка времени. Возможность отображать захваченные события перехода состояния в течение десяти секунд может помочь автоматизированным инструментам быстро выявлять проблемы и предотвращать их распространение.
Высокая доступность
Даже когда сетевые разделы возникают между разными контроллерами домена, службы внутри контроллеров домена должны иметь возможность записывать данные мониторинга в режиме реального времени и считывать данные из базы данных временных рядов в контроллерах домена.
Отказоустойчивость
Возможность репликации данных в несколько регионов может хорошо работать в случае проблемы с одним контроллером домена или целым географическим регионом.
Gorilla — это база данных временных рядов, разработанная с учетом всех вышеперечисленных требований.Его можно понимать как кеш со сквозной записью данных временных рядов.Поскольку данные находятся в памяти, Gorilla может обрабатывать большинство запросов в течение 10 миллисекунд. Благодаря исследованию хранилища оперативных данных (ODS, решение для базы данных временных рядов на основе HBase), которое долгое время использовалось в FB, было обнаружено, что более 85% запросов данных включают только данные, созданные за последние 26 лет. часов.Обнаружено, что если вместо базы данных на диске используется база данных в оперативной памяти, требования пользователя ко времени отклика могут быть удовлетворены.
Весной 2015 года система мониторинга в FB генерировала более 2 миллиардов наборов временных рядов, 12 миллионов в секунду и 1 триллион точек данных в день. Если предположить, что для каждой точки выборки требуется 16 байт памяти, это означает 16 ТБ памяти в день. Команда Gorilla сократила количество байтов, необходимых для каждой точки выборки, до 1,37 с помощью алгоритма сжатия с плавающей запятой на основе XOR, уменьшив общую потребность в памяти почти в 12 раз.
Для обеспечения доступности команда Gorilla развертывает несколько экземпляров Gorilla в разных регионах и контроллерах домена.Времена экземпляров синхронизируют данные друг с другом, но согласованность не гарантируется. Запросы на чтение данных будут перенаправлены в ближайший экземпляр Gorilla.
Предыстория и потребности
ОРВ
ODS является важной частью системы мониторинга онлайн-сервиса FB, которая состоит из базы данных временных рядов на основе HBash, службы запроса данных и системы оповещения. Его общая архитектура показана на следующем рисунке:
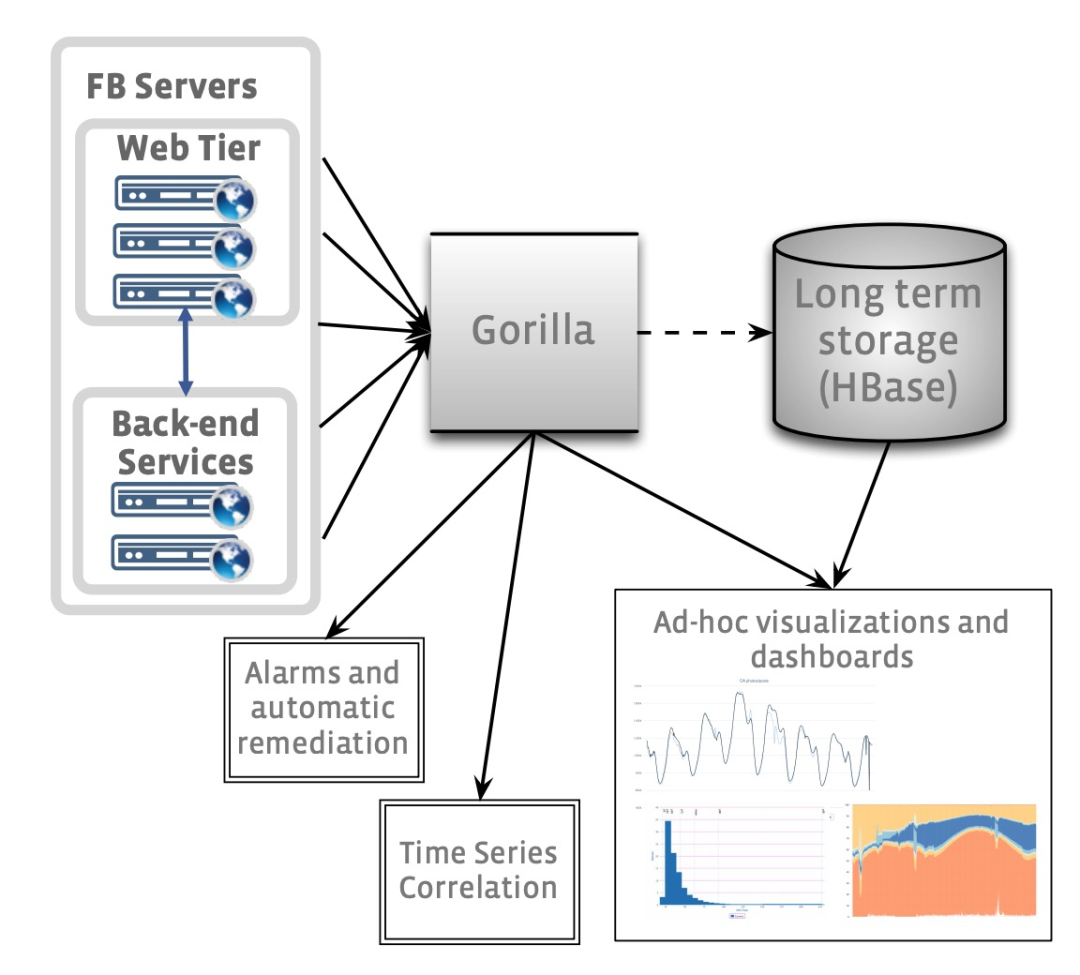
Потребители ОРВ в основном состоят из двух частей:
-
Интерактивная система диаграмм для разработчиков для анализа проблем -
Автоматическая система сигнализации
В начале 2013 года группа мониторинга FB поняла, что база данных временных рядов на основе HBase не может справиться с будущей нагрузкой чтения.Хотя задержка запроса данных во время анализа значков была терпимой, достижение 90-го квантиля запроса за несколько секунд заблокировало автоматическая сигнализация нормальной работы. Поскольку о других готовых решениях не могло быть и речи, группы мониторинга обратили свое внимание на решения для кэширования. Хотя ODS использует простой кэш сквозного чтения, это решение кэширует только общие данные временных рядов на нескольких диаграммах, но всякий раз, когда диаграмма запрашивает последние данные, все равно происходит промах кэша, когда данные считываются. HBase. Группа мониторинга также рассматривала возможность использования Memcache в качестве кеша со сквозной записью, но запись большого количества последних данных каждый раз приводила к большому трафику в memcache, и в конечном итоге это решение было отклонено. Группам мониторинга нужны более эффективные решения.
Горилле нужно
Ниже приводится изложение требований к новому решению:
-
2 миллиарда наборов данных различных временных рядов, каждый набор данных временных рядов идентифицируется уникальной строкой -
700 миллионов выборок данных в минуту -
Сохранить 26 часов полных данных -
Чтение данных завершено в течение 1 мс -
Минимальный поддерживаемый интервал выборки составляет 15 с. -
Два узла-реплики для поддержки отказоустойчивости, даже если один узел выйдет из строя, он сможет продолжать обрабатывать запросы на чтение -
Возможность быстрого сканирования всех данных памяти -
Поддерживает двукратный ежегодный рост
Сравнение с другими системами TSDB
Поскольку Gorilla предназначена для хранения всех данных в памяти, ее структура данных в памяти отличается от других баз данных временных рядов. Благодаря такому дизайну разработчики могут также рассматривать Gorilla как кеш со сквозной записью для баз данных временных рядов на основе дисков.
ОпенТСДБ
OpenTSDB — это решение для базы данных временных рядов, которое продолжает HBase, очень похожее на уровень хранения HBase в ODS. Структура таблиц обеих систем очень похожа, и также приняты аналогичные решения по оптимизации и горизонтальному расширению. Но, как упоминалось ранее, решения на основе дисков трудно поддерживать потребность в быстрых запросах. Уровень хранения ODS HBase будет намеренно снижать точность выборки старых данных, тем самым экономя общее занимаемое пространство; OpenTSDB сохранит полную точность данных. Принесение в жертву точности старых данных может привести к увеличению скорости запросов к старым данным и экономии места, что, по мнению команды FB, имеет смысл. Модель данных OpenTSDB для идентификации данных временных рядов богаче, чем у Gorilla, и каждая группа данных временных рядов может быть помечена любой группой данных ключ-значение, так называемыми тегами. Gorilla использует только строку для маркировки данных временных рядов и полагается на верхний уровень для извлечения информации, которая идентифицирует данные временных рядов.
Шепот (графит)
Graphite хранит данные временных рядов на локальном диске в формате Whisper. Формат Whisper предполагает, что интервал выборки данных временного ряда стабилен, если интервал выборки колеблется, Graphite ничего не может сделать. Напротив, если интервал выборки данных временного ряда стабилен, Gorilla может хранить данные более эффективно, а Gorilla также может работать с нестабильными интервалами. В Graphite каждый набор данных временных рядов существует в отдельном файле, и новые точки выборки перезаписывают старые данные в течение определенного периода времени; Gorilla похожа, но разница в том, что она хранит данные в памяти. Поскольку Graphite — это дисковая база данных временных рядов, она также не соответствует внутренним требованиям FB.
InfluxDB
Модель данных InfluxDB более выразительна, чем OpenTSDB, и каждая выборка во временном ряду может иметь полные метаданные, но такой подход также приводит к тому, что хранилище данных занимает больше места на диске. InfluxDB также поддерживает развертывание кластера и горизонтальное расширение, а группе эксплуатации и обслуживания не нужно управлять кластерами HBase/Hadoop. В FB уже есть специальная команда, отвечающая за работу и обслуживание кластера HBase, так что это не проблема для команды ODS. Подобно другим системам, InfluxDB также хранит данные на диске, и ее эффективность запросов намного ниже, чем у баз данных в памяти.
Горилла Архитектура
В Gorilla каждый образец данных временного ряда состоит из тройки:
-
строковый ключ: используется для идентификации временного ряда, к которому он принадлежит -
метка времени (int64): метка времени -
значение (float64): образец значения
Gorilla использует новый алгоритм сжатия временных рядов, который уменьшает пространство, необходимое для хранения каждой выборки данных временного ряда, с предыдущих 16 байтов до в среднем 1,37 байта.
Разделяя каждый набор данных временных рядов на определенный сервис Gorilla с помощью строкового ключа, можно легко добиться горизонтального расширения. Через восемнадцать месяцев после официального запуска Gorilla требуется около 1,3 ТБ памяти для хранения 26 часов данных, а для каждого кластера требуется 20 машин. На момент написания для каждого кластера уже требуется 80 машин.
Gorilla защищает от одиночных точек отказа, сетевых разделов и даже целых отказов DC, одновременно записывая данные временных рядов на две машины в разных регионах. Как только ошибка обнаружена, все запросы на чтение будут перенаправлены в службу в альтернативном регионе, чтобы гарантировать, что у пользователей нет явного восприятия ошибки.
сжатие временных рядов
У Gorilla есть два основных требования к алгоритму сжатия:
-
Потоковое сжатие: нет необходимости читать полные данные -
Сжатие без потерь: без потери точности данных
Сравнивая анализ данных непрерывной выборки, можно заметить, что:
-
Интервал между последовательными метками времени обычно постоянный, например 15 секунд. -
Разница в двоичном кодировании между последовательными значениями данных невелика
Поэтому Gorilla использует разные алгоритмы сжатия для меток времени и значений данных. Прежде чем анализировать конкретный алгоритм, вы можете посмотреть на общий процесс алгоритма:
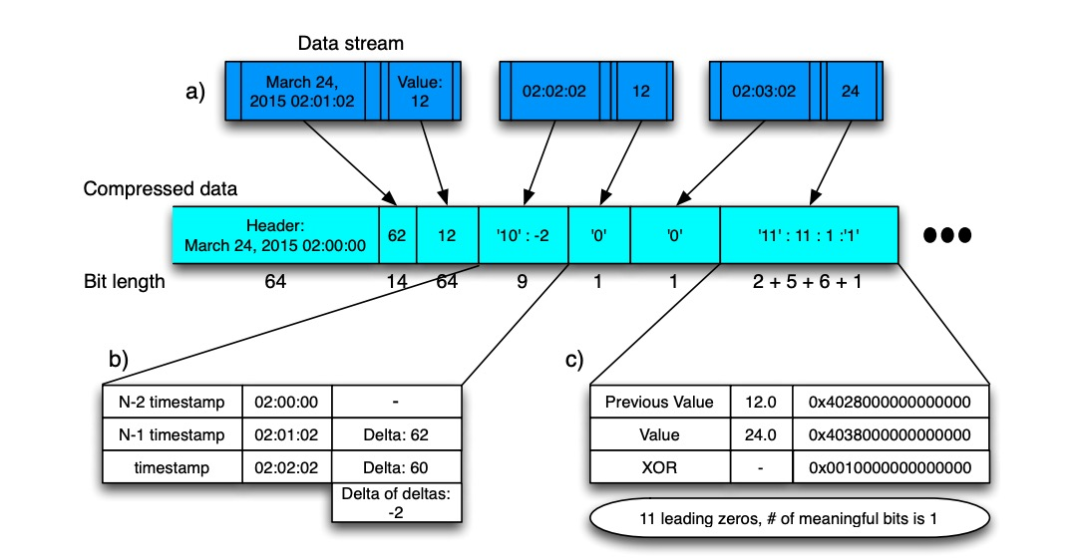
-
Метка времени начала записывается в начале каждого блока данных. -
Первые примерные данные -
Временная метка хранит разницу с начальной временной меткой. -
Значения данных хранятся как есть -
Начните со второго примера данных -
Отметка времени хранит дельту дельты -
Значения данных хранятся как различия
Сжатие меток времени
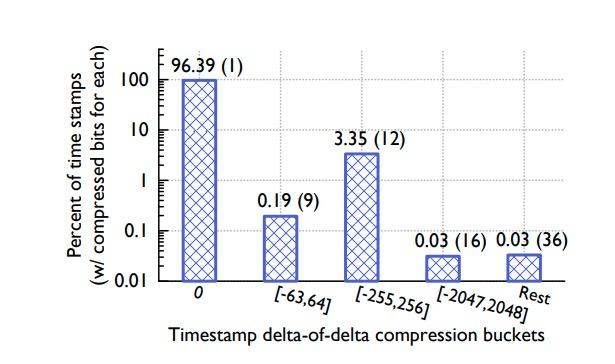
Анализируя данные временных рядов в ODS, команда Gorilla обнаружила, что большинство выборок временных рядов поступают в службу через фиксированные интервалы, например 60 секунд. Временное окно в целом стабильно, хотя время от времени бывают задержки или опережения на 1 секунду.
Предполагая, что дельта непрерывных меток времени составляет: 60, 60, 59, 61, тогда дельта дельты составляет: 0, -1, 2, поэтому через время начала, дельта первых данных и время начала, и все остальные Дельта дельты точки выборки может хранить полные данные.
Интервал, выбранный для D в алгоритме, позволяет получить максимальную степень сжатия на реальных данных. Данные временного ряда могут потерять точки данных в любое время, поэтому может появиться такая дельта-последовательность: 60, 60, 121, 59. В это время дельта дельты: 0, 61, -62 и 10 бит данных нужно хранить. На следующем рисунке показана статистическая производительность временного сжатия:
Сжатие значений
Анализируя данные из ODS, команда Gorilla заметила, что большинство значений данных смежных временных рядов существенно не различаются. В соответствии с форматом кодирования с плавающей запятой, определенным в IEEE 754:
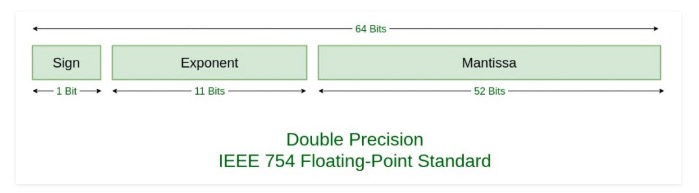
Обычно между соседними значениями некоторые биты перед знаком, показателем степени и мантиссом не изменяются, как показано на следующем рисунке:
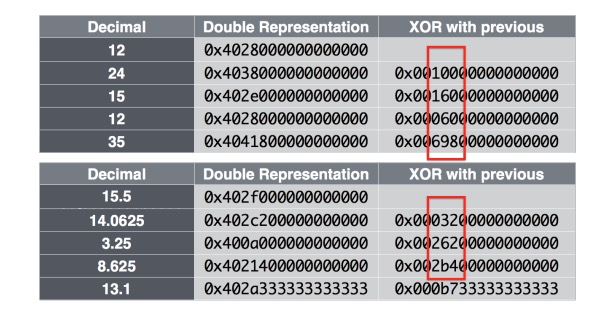
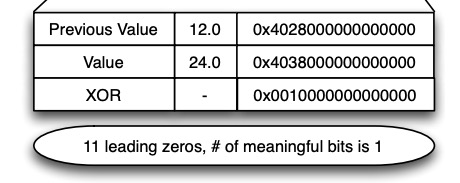
Таким образом, используя это, мы можем сжимать данные, записывая различную информацию в XOR соседних значений. Полный алгоритм выглядит следующим образом:
-
Первое значение хранится в несжатом виде -
Если результат XOR с предыдущим значением равен 0, то есть значение не изменилось, то сохранить 1 бит, '0' -
Если результат XOR с предыдущим значением не равен 0, сначала сохраните 1 бит, '1' -
(Бит управления «0»): если текущий интервал XOR находится в предыдущем интервале XOR, информация о положении предыдущего интервала XOR может быть повторно использована, и сохраняется только значение XOR внутри интервала. -
(Управляющий бит «1»): если текущий интервал XOR не находится в предыдущем интервале XOR, сначала используйте 5 бит для хранения номера префикса 0, затем используйте 6 бит для хранения длины интервала и, наконец, сохраните XOR. значение внутри интервала
Для получения подробной информации обратитесь к примеру на блок-схеме, а именно:
На следующем рисунке показана статистическая производительность алгоритма сжатия значений данных временных рядов:
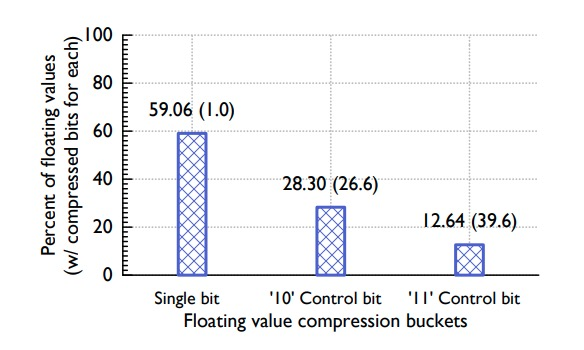
-
Для хранения 59% значений требуется всего 1 бит -
28% значений нужно всего 26,6 бит для хранения -
13% значений требуют для хранения 39,6 бит
Здесь необходимо учитывать компромисс: промежуток времени, охватываемый каждым блоком данных. Больший промежуток времени может обеспечить более высокую степень сжатия, но чем больше ресурсов требуется для распаковки, тем конкретные статистические результаты показаны ниже:
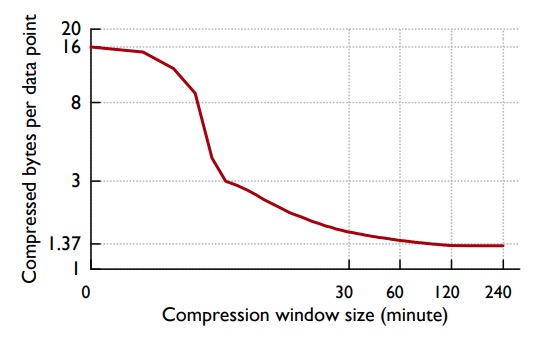
Из рисунка видно, что через 2 часа предельная выгода от увеличения степени сжатия за счет увеличения диапазона уже очень мала, поэтому Gorilla наконец выбирает временной интервал в 2 часа.
структуры данных в памяти
Структура данных в памяти Gorilla показана ниже.
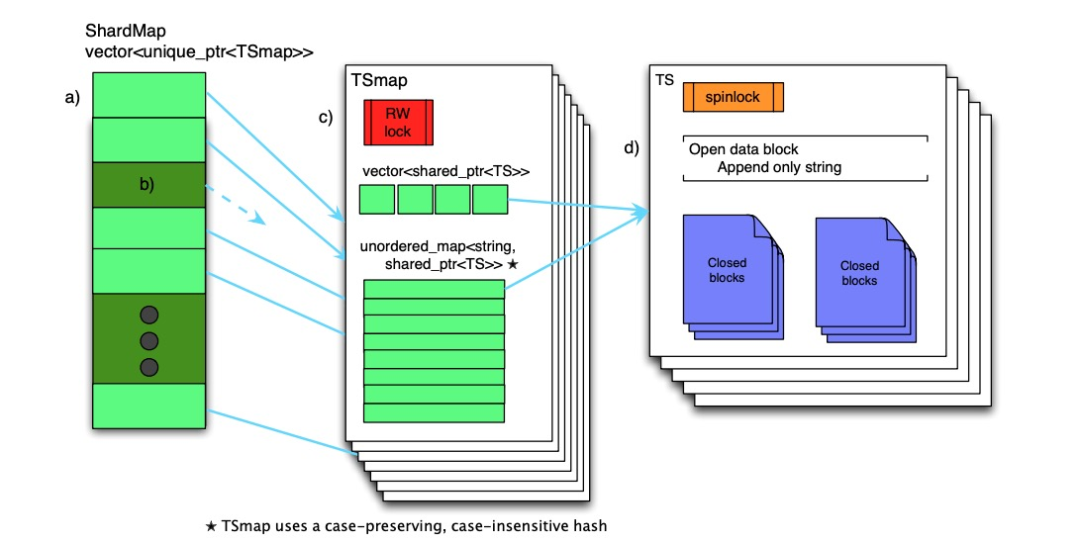
Всю структуру данных можно разделить на три слоя:
-
ShardMap -
ТСмап -
ТС
ShardMap
ShardMap поддерживается на каждом узле Gorilla, который отвечает за сопоставление хеш-значения имени временного ряда с соответствующим TSmap. Если соответствующий указатель на ShardMap пуст, данные целевого временного ряда не находятся на текущем узле (осколке). Поскольку количество осколков в системе постоянно и должно составлять порядка 3 цифр, стоимость хранения ShardMap невелика. Параллельный доступ к ShardMap контролируется циклической блокировкой чтения-записи.
ТСмап
TSmap — это индекс данных временных рядов. Он состоит из следующих двух частей:
-
Вектор указателей на все TS, помеченный как вектор -
Словарь, отображающий хэши имен временных рядов на указатели TS, помеченный как map
вектор используется для быстрого сканирования всех данных, карта используется для удовлетворения стабильных и быстрых запросов запросов. Управление параллелизмом TSmap реализовано с помощью спин-блокировки чтения-записи. При сканировании полных данных вам нужно только скопировать вектор, который состоит из пакета указателей, который очень быстр и имеет маленькую критическую секцию; при удалении данных он удаляется пометкой надгробной плиты и пассивно перерабатывается.
ТС
Каждый набор данных временных рядов состоит из серии блоков данных, каждый блок данных сохраняет данные за 2 часа, последний блок данных все еще открыт, и в нем хранятся самые последние данные. Данные могут быть добавлены только к последнему блоку данных.По истечении 2 часов блок данных будет закрыт.Закрытый блок данных не может быть изменен, пока память не будет очищена.
При чтении данных все блоки данных, участвующие в запросе, будут скопированы и возвращены непосредственно клиенту RPC, а процесс распаковки данных будет завершен клиентом.
структура диска
Gorilla 的设计目标之一就是能抵御单点故障,因此 Gorilla 同样需要通过持久化存储做故障恢复。Gorilla 选择的持久化存储是 GlusterFS,后者是兼容 POSIX 标准的分布式文件系统,默认 3 备份。其它分布式文件系统,如 HDFS 也可以使用。Gorilla 团队也考虑使用单机 MySQL 或者 RocksDB,但最终没有选择,原因是 Gorilla 并不需要使用查询语言支持。
一个 Gorilla 节点会维持多个分片的数据,于是它会为每个分片建立一个文件夹。每个文件夹中包含四类文件:
-
Key Lists -
Append-only Logs -
Complete Block Files -
Checkpoint Files
Key Lists
Key Lists 实际上就是时序名称到 integer identifier 的映射,后者是时序在 TSmap vector 中的偏移值。Gorilla 会周期性地更新 Key Lists 数据。
Append-only Logs
当所有时序数据的样本点流向 Gorilla 节点时,Gorilla 会将他们压缩后的数据交织地写入日志文件中。但这里的日志文件并不是 WAL,Gorilla 也并没有打算提供 ACID 支持,当日志数据在内存中满 64 KB 后会被追加到 GlusterFS 中相应的日志文件中。故障发生时,将有可能出现少量数据丢失,但为了提高写吞吐,这个牺牲还算值得。
Complete Block Files
每隔 2 小时,Gorilla 会将数据块压缩后复制到 GlusterFS 中。每当一块数据持久化完成后,Gorilla 就会创建一个 checkpoint 文件,同时删除相应的日志文件。checkpoint 文件被用来标识数据块持久化成功与否。故障恢复时,Gorilla 会通过 checkpoint 和日志文件载入之前的数据。
容错
在容错方面,Gorilla 优先支持以下场景:
-
单点故障,如果是临时故障则客户端完全无感知,常用于新版发布 -
大范围、区域性故障:如 region 范围的网络分区
高可用
Gorilla поддерживает доступность службы, поддерживая два отдельных экземпляра на контроллерах домена в двух разных регионах. Когда один и тот же набор последовательных данных записывается, он будет отправлен в эти два независимых экземпляра, но атомарность двух операций записи не гарантируется. При сбое в одном регионе будут предприняты попытки чтения для другого региона. Если регион выходит из строя более 1 минуты, запросы на чтение не будут отправляться в него до тех пор, пока данные экземпляра в регионе не будут нормально записаны в течение 26 часов.
Внутри каждой зоны используется ShardManager на основе Paxos для поддержания связи между осколками и узлами. Когда узел выходит из строя, ShardManager перераспределяет поддерживаемые им сегменты другим узлам в кластере. Перенос сегмента обычно может быть завершен в течение секунд 30. Во время процесса передачи сегмента клиент, который записывает данные, кэширует данные, которые должны быть записаны, и кэширует данные максимум за последнюю минуту. Когда клиент обнаружит, что операция передачи сегмента завершена, он немедленно очистит кеш и запишет данные на узел. Если передача сегмента слишком медленная, запросы на чтение можно вручную или автоматически перенаправлять в другой регион.
Когда новый сегмент назначается узлу, этот узел должен прочитать все данные из GlusterFS. Обычно загрузка и предварительная обработка этих данных занимает 5 минут. Пока узел восстанавливает данные, вновь записанные образцы данных временных рядов помещаются в очередь ожидания. После сбоя старого узла запрос на чтение может прочитать часть данных и пометить их до того, как новый узел завершит загрузку данных сегмента. Если клиент обнаружит, что данные помечены как частичные, он снова запросит данные в другой области и вернет последние, если данные полные, и вернет два набора частичных данных, если это не удается.
Наконец, FB по-прежнему использует HBase TSDB для хранения долгосрочных данных, и инженеры по-прежнему могут использовать его для анализа данных прошлых временных рядов.
Новые инструменты на Gorilla
Поскольку данные Gorilla хранятся в памяти, это позволяет проводить анализ в реальном времени.
-
Механизм корреляционного анализа в основном используется для быстрого обнаружения сильно коррелированных данных временных рядов, чтобы помочь в анализе первопричин. -
рисунок на мониторе -
Совокупный анализ
Адрес статьи: http://www.vldb.org/pvldb/vol8/p1816-teller.pdf
Оригинальный перевод: https://zhenghe.gitbook.io/open-courses/papers-we-love/gorilla-a-fast-scalable-in-memory-time-series-database