
Будьте внимательны, не заблудитесь в галантерее👆
Была проблема
Есть сигнализация! ! !
В один из дней, когда я перемещал кирпичи, я обнаружил, что некоторые экземпляры сервиса bytedance.xiaoming микросервиса имеют слишком большой объем памяти, достигающий 80%. И этот сервис давно не запускал новую версию, так что проблемы, связанные с новым кодом онлайн, можно исключить.
После обнаружения проблемы инстансы сначала были перенесены. За исключением одного инстанса, который был зарезервирован для устранения неполадок, остальные инстансы были мигрированы. После миграции у нового инстанса стало мало памяти. Однако обнаружено, что память перенесенного экземпляра также медленно увеличивается с течением времени, и имеет место утечка памяти.
выявить проблему
Предположение 1: подозрение на побег горутины
Процесс устранения неполадок
Обычно основной причиной утечек памяти является слишком много горутин, поэтому в первую очередь я подозреваю, есть ли проблема с горутинами.Я пошел посмотреть горутины и обнаружил, что они нормальные, общее количество мало и нет непрерывный рост. (Я забыл тогда сделать скриншот, а позже добавил картинку, но количество горутин не изменилось)
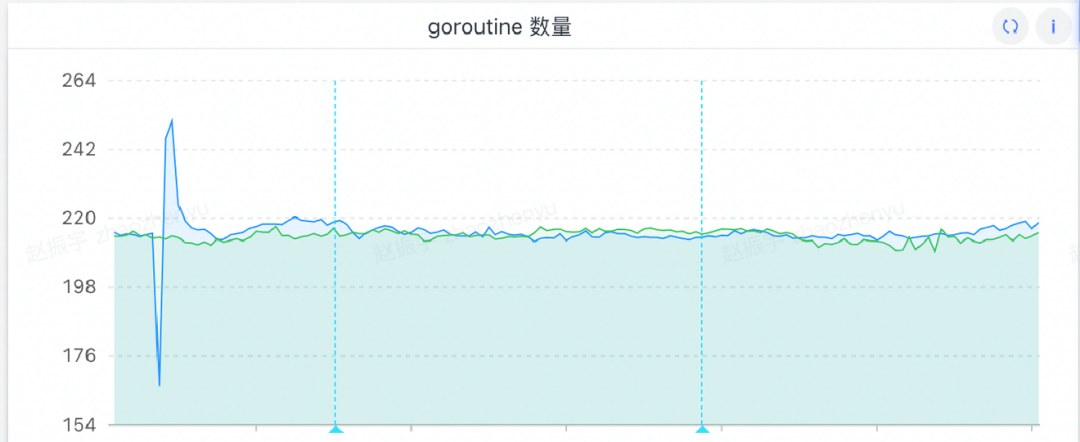
Результаты устранения неполадок
Нет проблем с выходом из горутины.
Предположение 2: подозрение на утечку памяти в коде
Процесс устранения неполадок
Выполните сбор памяти в реальном времени через pprof и сравните использование памяти проблемным экземпляром и обычным экземпляром:
Пример проблемы:

Нормальный пример:

Посмотрите далее на график проблемного экземпляра:
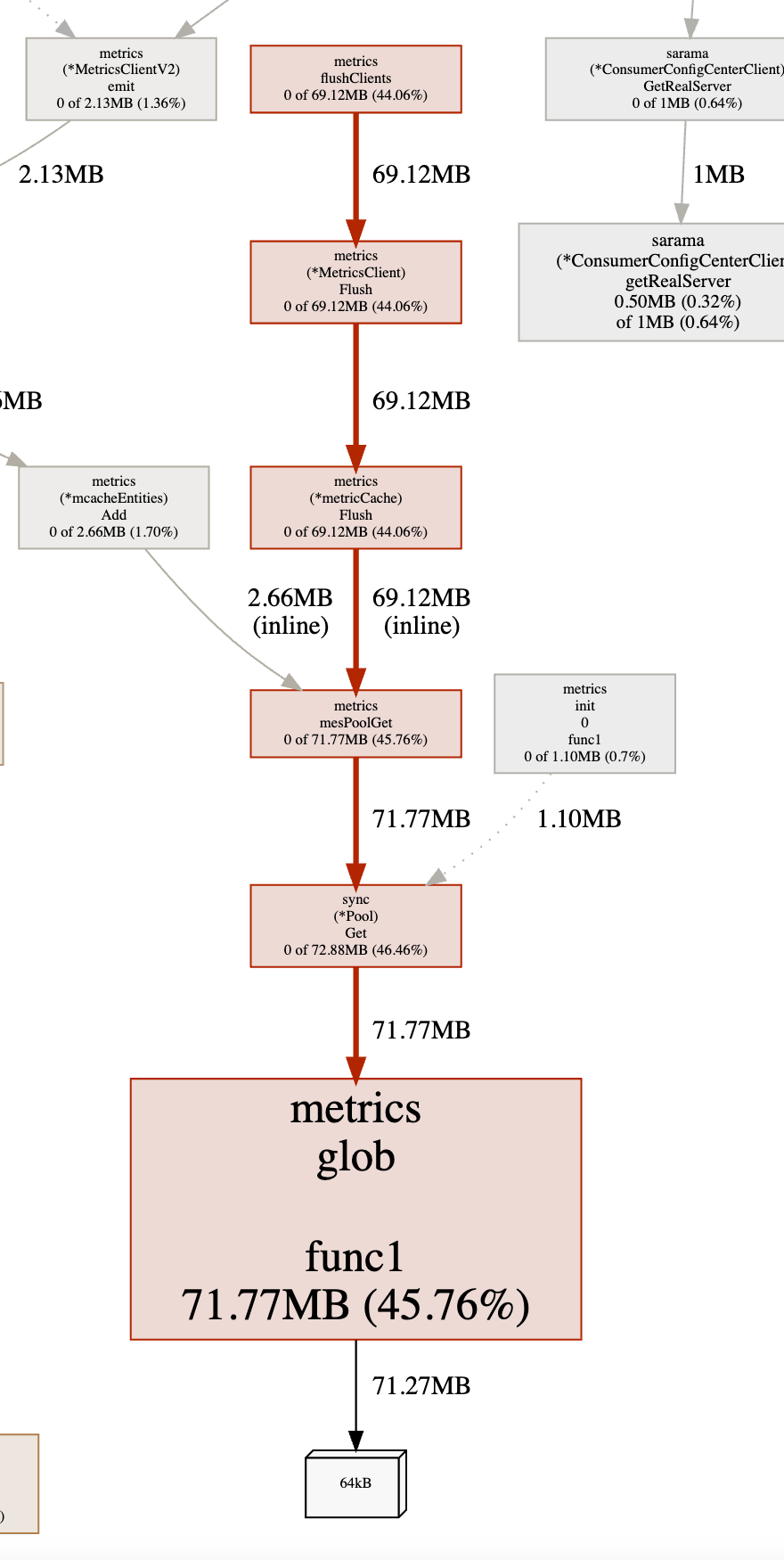
Отсюда видно, что metircs.flushClients() занимает больше всего памяти.Чтобы найти исходный код:
func (c *tagCache) Set(key []byte, tt *cachedTags) {
if atomic.AddUint64(&c.setn, 1)&0x3fff == 0 {
// every 0x3fff times call, we clear the map for memory leak issue
// there is no reason to have so many tags
// FIXME: sync.Map don't have Len method and `setn` may not equal to the len in concurrency env
samples := make([]interface{}, 0, 3)
c.m.Range(func(key interface{}, value interface{}) bool {
c.m.Delete(key)
if len(samples) < cap(samples) {
samples = append(samples, key)
}
return true
}) // clear map
logfunc("[ERROR] gopkg/metrics: too many tags. samples: %v", samples)
}
c.m.Store(string(key), tt)
}
Выяснилось, что во избежание утечек памяти ключи, хранящиеся в sync.Map, были очищены путем подсчета. По идее проблем быть не должно.
Результаты устранения неполадок
Нет ошибок кода, вызывающих утечку памяти.
Предположение 3: подозревается проблема с RSS
Процесс устранения неполадок
В это время я заметил одну вещь.В pprof я увидел, что метрики занимают всего 72 МБ в сумме, а общая память в куче всего 170+ МБ.Наш инстанс настроен на 2 ГБ памяти, и занимает 80% памяти означает, что RSS занимает около 1,6 ГБ. , эти два параметра серьезно несовместимы (временное решение этой проблемы будет представлено позже), что не должно вызывать тревогу использования памяти на 80%. Следовательно, предполагается, что память не восстанавливается вовремя.
После расследования я нашел эту волшебную вещь:
Долгое время, когда рантайм go освобождает память и возвращается к ядру, он используется на Linux MADV_DONTNEED, хотя эффективность относительно низкая, но количество RSS (размер резидентного набора памяти, размер резидентного набора памяти) быстро уменьшается. Однако в go 1.12 она специально оптимизирована для этого, когда рантайм освобождает память, то MADV_FREE вместо предыдущей использует более эффективную MADV_DONTNEED. Подробное введение можно найти здесь:
https://go-review.googlesource.com/c/go/+/135395/
Обновленный исходный текст go1.12:
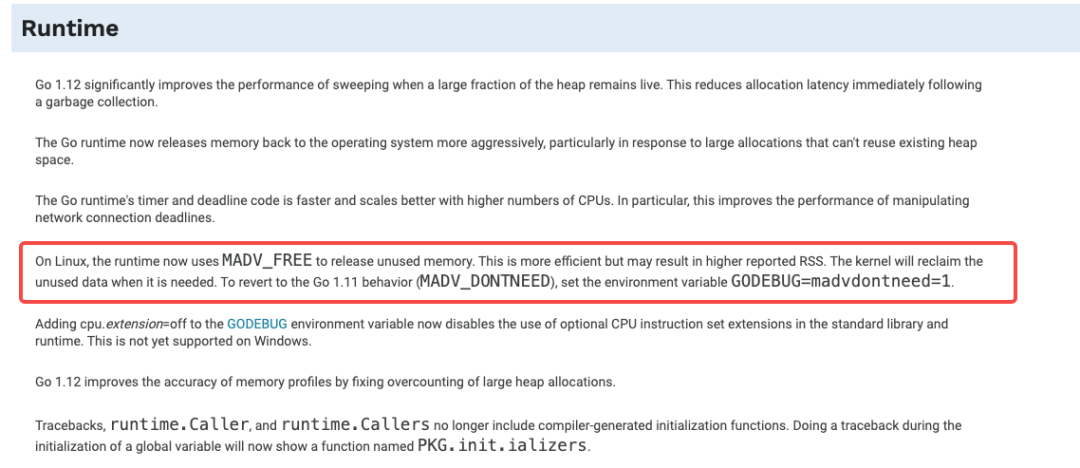
Среда выполнения Go 1.12~1.15 оптимизирует стратегию GC.При поддержке версии ядра Linux (> 4.5) по умолчанию будет принята более «агрессивная» стратегия, чтобы сделать повторное использование памяти более эффективным, снизить задержку и многие другие оптимизации. Недостатком является то, что RSS не отключается сразу, а откладывается до тех пор, пока память не окажется под нагрузкой.
Наша версия Go — 1.15, версия ядра — 4.14, просто достигните цели!
Результаты устранения неполадок
Версия компилятора go + версия ядра системы соответствует стратегии gc во время выполнения go, так что RSS не будет падать после освобождения памяти кучи.
задача решена
Решение
Есть два решения:
-
Один из них - указать в переменной окружения GODEBUG=madvdontneed=1
Этот метод может заставить среду выполнения продолжать использовать файлы
MADV_DONTNEED.(Ссылка: https://github.com/golang/go/issues/28466). Но после запуска madvise не нужно, это вызовет перестрелку TLB и другие ошибки страницы. Компании, чувствительные к задержкам, могут пострадать в большей степени. Поэтому эту переменную среды нужно использовать с осторожностью!
-
Обновите версию компилятора go до версии выше 1.16.
См. примечания к обновлению для go 1.16. От этой стратегии GC отказались, и память освобождается вовремя вместо отложенного освобождения, когда память находится под давлением. Похоже, что официальный сайт go тоже считает способ освобождения памяти по времени более предпочтительным, и в большинстве случаев более подходящим.
Вложение: Чтобы решить проблему, заключающуюся в том, что куча, используемая pprof, намного меньше, чем RSS, ее можно решить, вызвав вручную debug.FreeOSMemory, но за выполнение этой операции приходится платить.

При этом FreeOSMemory не работает в версии go1.13 (https://github.com/golang/go/issues/35858), использовать ее рекомендуется с осторожностью.
Результаты внедрения
Мы выбрали второй вариант. После обновления go1.16 экземпляр не показывает явление, что память продолжает быстро расти.
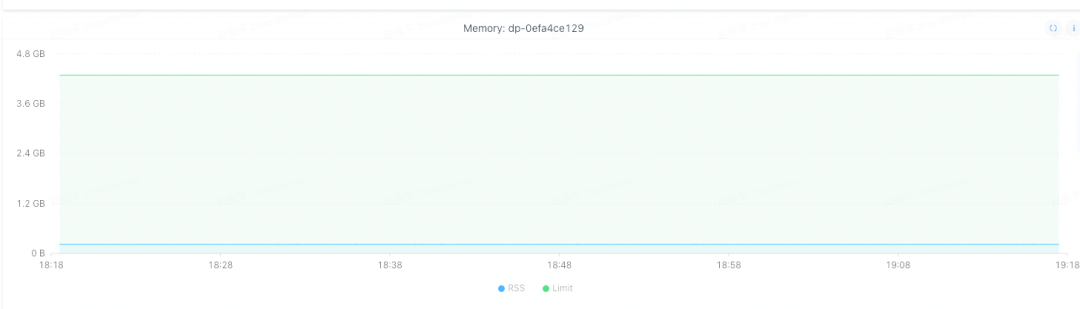
Снова используйте pprof, чтобы увидеть ситуацию с экземпляром и обнаружить, что функции, занимающие память, также меняются. metrics.glob, который раньше занимал память, перестал работать. Кажется, этот обходной путь работает.
Встречаются другие ямы
В процессе устранения неполадок была обнаружена еще одна проблема, которая может вызвать утечку памяти (эта служба не поражена).
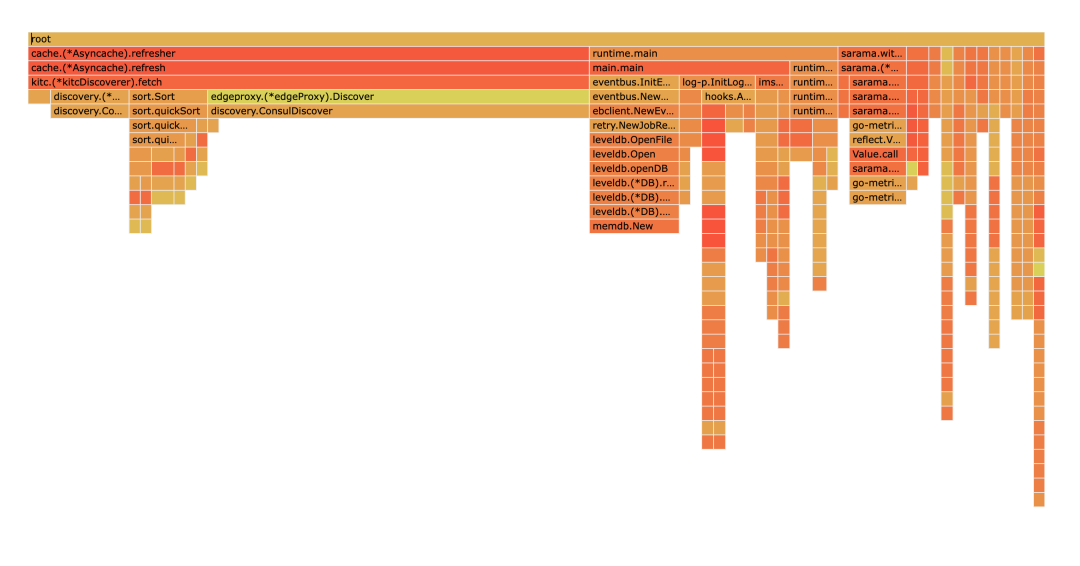
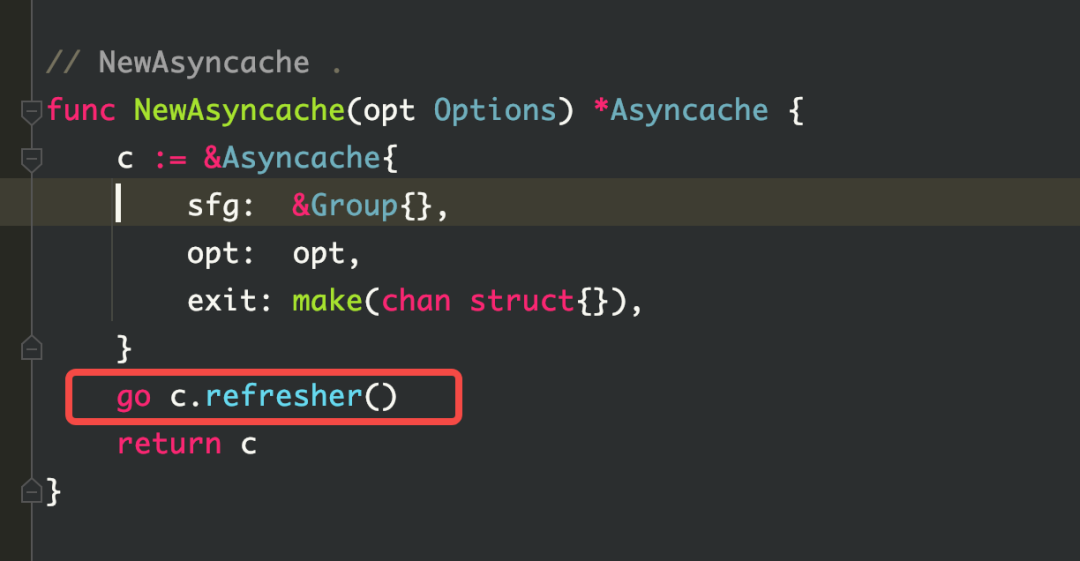
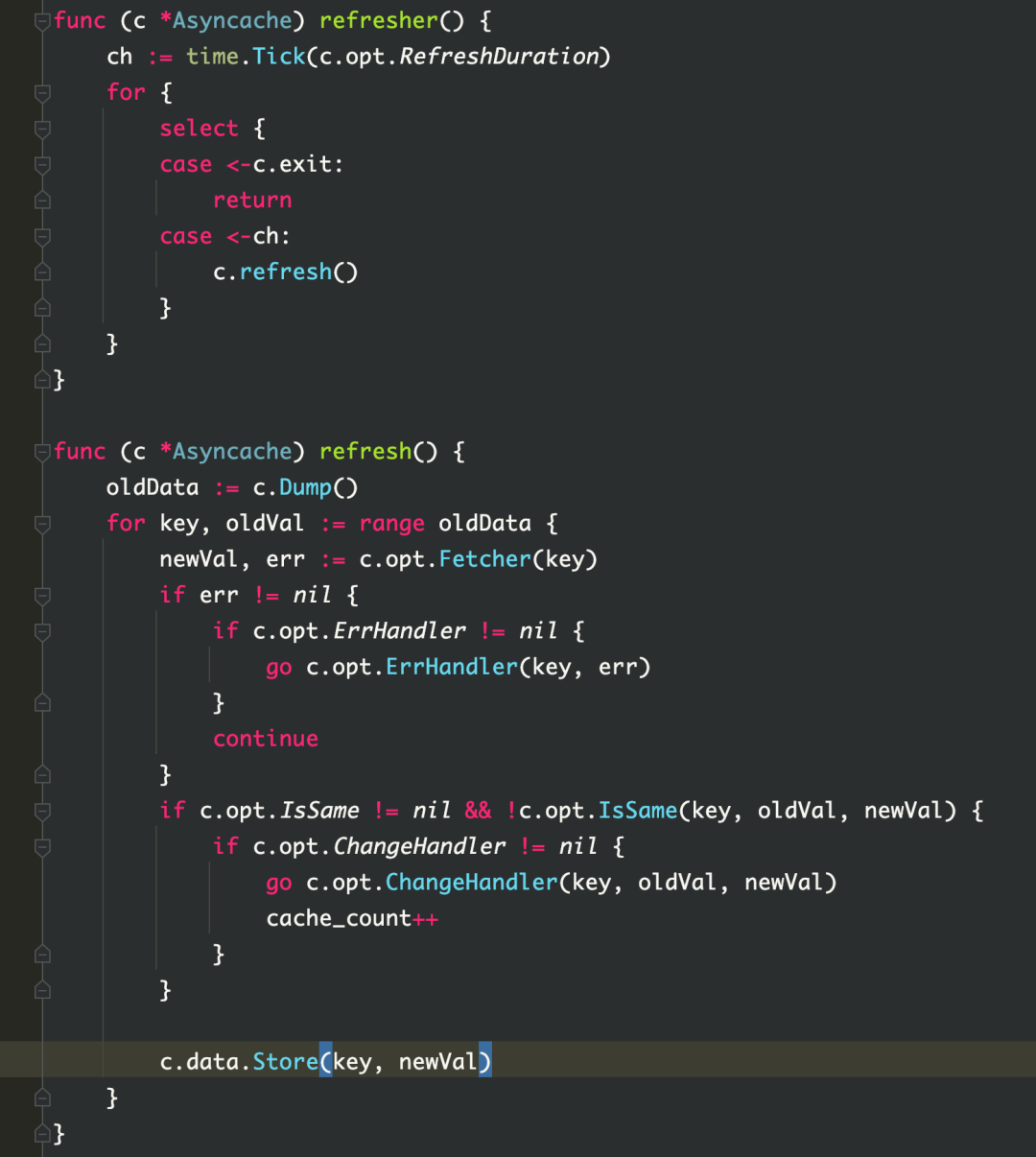
Как видно из рисунка, cache.(*Asynccache).refresher занимает много памяти, и по мере увеличения объема бизнес-процессов использование памяти будет продолжать расти.
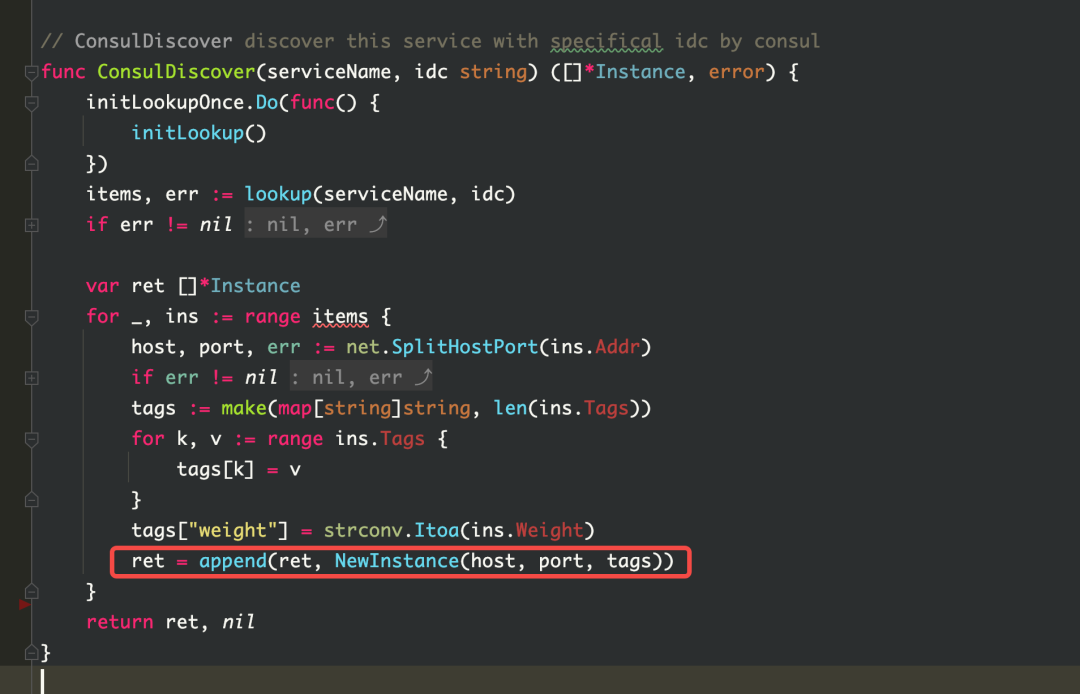
Естественно думать, что когда кайтклиент создается заново, могут быть случаи, когда клиент создается повторно. Поэтому была проведена проверка кода, и повторного построения не обнаружено. Но глядя на исходный код kitc, вы можете обнаружить, что при обнаружении службы в kitc устанавливается пул кеша asynccache для хранения экземпляра. Этот пул кеша будет обновляться каждые 3 секунды. При обновлении будет вызвана функция fetch, которая выполнит обнаружение службы. Во время обнаружения службы экземпляры будут непрерывно создаваться в соответствии с хостом, портом и тегами экземпляра (которые будут изменены в соответствии с окружением среды), а затем экземпляры будут храниться в кэш-пуле asynccache.Эти экземпляры не почистил а память не освобождается. Так вот что вызвало утечку памяти.
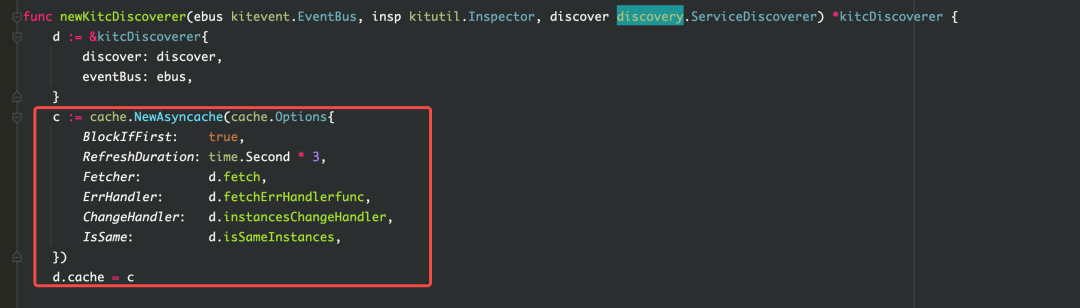
Решение
Проект относительно ранний, поэтому используемый фреймворк относительно старый.Эта проблема может быть решена путем обновления последнего фреймворка.
Резюме мыслей
Сначала определите, что такое утечка памяти:
Утечка памяти (Memory Leak) относится к тому факту, что динамически выделенная динамическая память в программе не освобождается или не может быть освобождена по какой-либо причине, что приводит к трате системной памяти, что приводит к серьезным последствиям, таким как замедление работы программы и даже системный сбой.
Общие сценарии
В сценарии go общие проблемы с утечкой памяти выглядят следующим образом:
1. Горутина вызывает утечку памяти
(1) Слишком много горутин-приложений
Обзор проблемы:
Слишком много горутин-приложений, и скорость роста выше, чем скорость выпуска, что приведет к появлению все большего количества горутин.
Пример сценария:
На один запрос создается новый клиент.Когда объем бизнес-запросов большой, создается слишком много клиентов и уже поздно освобождать.
(2) блокировка горутин
① Проблема с вводом/выводом
Обзор проблемы:
Соединение ввода-вывода не имеет тайм-аута, из-за чего горутина все время ожидает.
Пример сценария:
При запросе стороннего интерфейса сетевого подключения результат возврата не получен из-за проблем с сетью.Если период тайм-аута не установлен, код всегда будет блокироваться.
② Мьютекс не выпущен
Обзор проблемы:
Горутина не может получить ресурс блокировки, что приводит к блокировке горутины.
Пример сценария:
Предполагая, что есть общая переменная, goroutineA блокирует общую переменную, но не освобождает ее, так что другие goroutineB, goroutineC, ..., goroutineN не могут получить ресурс блокировки, вызывая блокировку других goroutine.
③ Неправильное использование группы ожидания
Обзор проблемы:
Количество команд «Добавить», «Готово» и «Ожидание» группы ожидания не совпадает, что приводит к постоянному ожиданию ожидания.
Пример сценария:
WaitGroup можно понимать как менеджер горутин. Ему нужно знать, сколько горутин у него работает, и нужно уведомить его, когда это будет сделано, иначе он будет ждать, пока все младшие братья не сделают. После того, как мы добавим группу ожидания, программа будет ждать, пока не получит достаточное количество сигналов Done(). Предположим, группа ожидания Add(2), Done(1), тогда в данный момент одна задача остается незавершенной, поэтому группа ожидания будет ждать все время. Для получения дополнительной информации см. главу группы ожидания в Горутинном механизме выхода.
2. выберите блокировку
Обзор проблемы:
Используйте select, но кейс не полностью покрыт, в результате чего кейс не готов, и в конечном итоге горутина блокируется.
Пример сценария:
Обычно это происходит, когда случай выбора не полностью раскрыт и нет значения по умолчанию, что приведет к блокировке. Пример кода выглядит следующим образом:
func main() {
ch1 := make(chan int)
ch2 := make(chan int)
ch3 := make(chan int)
go Getdata("https://www.baidu.com",ch1)
go Getdata("https://www.baidu.com",ch2)
go Getdata("https://www.baidu.com",ch3)
select{
case v:=<- ch1:
fmt.Println(v)
case v:=<- ch2:
fmt.Println(v)
}
}
3. Блокировка канала
Обзор проблемы:
-
блокировка записи -
Блокировка небуферизованного канала обычно является блокировкой операции записи, потому что нет чтения -
Запись в буферизованный канал заблокирована, так как буфер заполнен -
блокировка чтения -
Ожидая чтения данных из канала, в результате нет горутины для записи.
Пример сценария:
Ошибки кода по трем вышеуказанным причинам могут привести к блокировке канала.Вот несколько примеров реальной блокировки канала в производственной среде:
-
Сводка сбоев компьютера с библиотекой Lark_cipher -
Анализ утечек Горутины Шифра
4. Неправильное использование таймеров
(1) Неправильное использование time.after()
Обзор проблемы:
默认的 time.After()是会有内存泄漏问题的,因为每次 time.After(duratiuon x)会产生 NewTimer(),在 duration x 到期之前,新创建的 timer 不会被 GC,到期之后才会 GC。
那么随着时间推移,尤其是 duration x 很大的话,会产生内存泄漏的问题。
场景举例:
func main() {
ch := make(chan string, 100)
go func() {
for {
ch <- "continue"
}
}()
for {
select {
case <-ch:
case <-time.After(time.Minute * 3):
}
}
}
(2)time.ticker 未 stop
问题概述:
使用 time.Ticker 需要手动调用 stop 方法,否则将会造成永久性内存泄漏。
场景举例:
func main(){
ticker := time.NewTicker(5 * time.Second)
go func(ticker *time.Ticker) {
for range ticker.C {
fmt.Println("Ticker1....")
}
fmt.Println("Ticker1 Stop")
}(ticker)
time.Sleep(20* time.Second)
//ticker.Stop()
}
建议:总是建议在 for 之外初始化一个定时器,并且 for 结束时手工 stop 一下定时器。
5. slice 引起内存泄露
问题概述:
-
两个 slice 共享地址,其中一个为全局变量,另一个也无法被 gc; -
append slice 后一直使用,未进行清理。
场景举例:
-
直接上代码,采用此方式,b 数组是不会被 gc 的。
var a []int
func test(b []int) {
a = b[:3]
return
}
-
在遇到的其他坑里提到的 kitc 的服务发现代码就是这个问题的示例。
排查思路总结
今后遇到 golang 内存泄漏问题可以按照以下几步进行排查解决:
-
观察服务器实例,查看内存使用情况,确定内存泄漏问题;
-
可以在 tce 平台上的【实例列表】处直接点击;
-
也可以在 ms 平台上的【运行时监控】进行查看;
-
判断 goroutine 问题;
-
这里可以使用 1 中提到的监控来观察 goroutine 数量,也可以使用 pprof 进行采样判断,判断 goroutine 数量是否出现了异常增长。
-
判断代码问题;
-
利用 pprof,通过函数名称定位具体代码行数,可以通过 pprof 的 graph、source 等手段去定位; -
排查整个调用链是否出现了上述场景中的问题,如 select 阻塞、channel 阻塞、slice 使用不当等问题,优先考虑自身代码逻辑问题,其次考虑框架是否存在不合理地方;
-
解决对应问题并在测试环境中观察,通过后上线进行观察;
推荐的排查工具
-
pprof: 是 Go 语言中分析程序运行性能的工具,它能提供各种性能数据包括 cpu、heap、goroutine 等等,可以通过报告生成、Web 可视化界面、交互式终端 三种方式来使用 pprof -
Nemo:基于 pprof 的封装,采样单个进程 -
ByteDog:在 pprof 的基础上提供了更多指标,采样整个容器/物理机 -
Lidar:基于 ByteDog 的采样结果分类展示(目前是平台方更推荐的工具,相较于 nemo 来说) -
睿智的 oncall 小助手:kite 大佬研究的排查问题小工具,使用起来很方便,在群里 at 机器人,输入 podName 即可
加入我们
飞书是字节跳动旗下先进企业协作与管理平台,围绕目标、信息与人三个维度全方位助力组织升级。一站式整合即时沟通、日历、音视频会议、文档、云盘等办公协作套件,让组织和个人工作更高效更愉悦。飞书目前已服务包括互联网、信息技术、制造、建筑地产、教育、媒体在内等众多领域的先进企业。我们是飞书的Lark Core Services 团队,负责飞书核心的 IM 领域能力,包括消息、群组、用户资料、开放能力等等。期待您的加入~
社招链接:
https://job.toutiao.com/s/Ne1ovPK
校招链接(暑期实习)
https://jobs.toutiao.com/s/NJ3oxsp
 点击“阅读原文”了解岗位详情!
点击“阅读原文”了解岗位详情!