|Эта статья взята из блога 51cto.
Некоторые приемы мониторинга приложений с помощью Promethues
В этой статье мы рассказали, как использовать Prometheus для мониторинга приложений. В последующей работе, по мере углубления мониторинга, мы объединили собственный опыт и официальные документы, чтобы обобщить некоторые практики Метрики. Я надеюсь, что эти практики могут послужить вам ориентиром.
Определите, что отслеживать
Перед конкретным проектированием Метрики необходимо сначала уточнить объекты, которые необходимо измерить. То, что необходимо измерить, должно быть определено на основе контекста конкретной проблемы, потребностей и системы, подлежащей мониторингу.
Начните с потребностей
Основываясь на опыте большого количества распределенного мониторинга, компания Google подытожила четыре золотых индикатора мониторинга, которые имеют хорошее эталонное значение для объектов общего мониторинга и измерений. Четыре индикатора:
-
Задержка: время обслуживания запроса.
-
Трафик: отслеживает текущий системный трафик для измерения потребности службы в пропускной способности.
-
Ошибки. Отслеживайте все запросы об ошибках, возникающие в текущей системе, и измеряйте скорость возникновения ошибок в текущей системе.
-
Насыщенность: измеряет насыщенность текущего сервиса. Основной упор делается на ограниченные ресурсы, которые больше всего влияют на состояние сервиса. Например, если на систему в первую очередь влияет память, сосредоточьтесь в первую очередь на состоянии памяти системы.
Вышеуказанные четыре индикатора фактически соответствуют четырем требованиям мониторинга:
-
Отразите пользовательский опыт и измерьте основную производительность системы. Например: задержка онлайн-системы, время выполнения задания вычислительной системой и т. д.
-
Отражает пропускную способность системы. Такие как: количество запросов, размер отправленных и полученных сетевых пакетов и т.д.
-
Помогает найти и локализовать неисправности и проблемы. Такие как: количество ошибок, частота неудачных вызовов и т. д.
-
Отражает насыщенность и загрузку системы. Такие как: занимаемая системой память, длина очереди заданий и т.д.
В дополнение к вышеуказанным обычным требованиям, согласно конкретным сценариям проблем, для устранения и обнаружения проблем, которые возникали или могут возникнуть ранее, могут быть определены соответствующие объекты измерения. Например, интерфейс библиотеки, который система должна часто вызывать, может занять много времени или время от времени давать сбои.Можно сформулировать метрики для измерения задержки и количества сбоев этого интерфейса.
Начните с системы, которую необходимо контролировать
Чтобы соответствовать соответствующим требованиям, объекты измерения, за которыми должны наблюдать разные системы, также различны. В соответствии с передовой практикой официального документа приложения, которые необходимо отслеживать, делятся на три категории:
-
Системы онлайн-обслуживания: необходимо немедленно ответить на запрос, и запрашивающая сторона будет ждать ответа. например веб-сервер.
-
Автономная обработка: запрашивающий не ждет ответа, и запрошенное задание обычно занимает много времени. Например, среда пакетных вычислений Spark и так далее.
-
Пакетные задания. Эти типы приложений обычно одноразовые, не выполняются постоянно и завершаются после завершения операции. Например, задания MapReduce для анализа данных.
Объекты, которые обычно измеряются, различны для каждого типа приложения. Его резюме выглядит следующим образом:
-
Система онлайн-сервиса: в основном включают запросы, количество ошибок и задержку запросов.
-
Автономная вычислительная система: время последней обработки задания, количество обрабатываемых в настоящее время заданий, количество отправленных элементов, длина очереди заданий и т. д.
-
Пакетное задание: момент последнего успешного выполнения, время выполнения каждого основного этапа, общее затраченное время, количество обработанных записей и т. д.
Помимо самой системы, иногда необходимо мониторить подсистемы:
-
Используемые библиотеки: количество вызовов, количество успехов, количество ошибок и задержка вызова.
-
Ведение журнала: подсчитывает каждый записанный журнал, чтобы узнать, как часто и когда происходит каждый журнал.
-
Сбои: количество ошибок.
-
Пул потоков: количество запросов в очереди, количество используемых потоков, общее количество потоков, затраты времени, количество обрабатываемых задач и т. д.
-
Кэш: количество запросов, попаданий, общая задержка и т. д.
Выберите вектор
Принцип выбора Век:
-
Похожие типы данных, но разные типы ресурсов, места сбора и т. д.
-
Единство данных внутри Vec
пример:
-
Задержка запроса для различных объектов ресурсов
-
Задержка запроса для разных геосерверов
-
Количество различных ошибок HTTP-запроса…
Кроме того, в официальной документации предлагается, чтобы разные операции объекта ресурса, такие как чтение/запись, отправка/получение, записывались в разных метриках, а не в одной метрике. Причина в том, что они обычно не объединяются во время мониторинга, а наблюдаются отдельно. Однако для измерения запроса обычно используется метка, чтобы различать разные действия.
Определить метку
Общие варианты этикеток:
-
ресурс
-
область, край
-
тип…
Важным принципом определения Label является то, что данные одной и той же размерности Label можно усреднить и сложить, то есть единица должна быть унифицирована. Например, скорость вращения вентилятора и напряжение не могут быть помещены в метку.
Кроме того, не рекомендуются следующие действия:
копировать
my_metric{label=a} 1 my_metric{label=b} 6 my_metric{label=total} 7
1.
То есть в Label учитываются как баллы, так и итоговые данные, для получения итогового результата рекомендуется использовать PromQL для агрегации на стороне сервера. Или используйте другую метрику для измерения общих данных.
Именование метрик и меток
Хорошее название видно по названию, так что название также является частью хорошего дизайна.
Название метрики:
-
prometheus_notifications_total
-
process_cpu_seconds_total
-
IPamd_request_latency
-
Необходимо соответствовать шаблону: a-zA-Z:
-
В качестве префикса должен содержать слово, указывающее домен, к которому относится данная метрика.как:
-
Должен включать единицу измерения в качестве суффикса для обозначения единицы измерения этого показателя.как:
-
http_request_duration_seconds
-
node_memory_usage_bytes
-
http_requests_total (для накопления счетчика без единиц измерения)
-
Логически имеет то же значение, что и измеряемая переменная.
-
Попробуйте использовать основные единицы измерения, такие как секунды, байты. Вместо миллисекунд мегабайты.
Название ярлыка:
Назван в соответствии с выбранным параметром, например:
-
регион: Шэньчжэнь/Гуанчжоу/Пекин
-
владелец: пользователь1/пользователь2/пользователь3
-
этап: извлечение/преобразование/загрузка
Выбор ковшей
Соответствующие корзины могут сделать процентный расчет гистограммы более точным.
В идеале корзины сделают распределение данных ступенчатым, то есть количество данных в каждом интервале корзин будет примерно одинаковым.
При проектировании ковшей можно следовать следующему опыту:
-
Вам необходимо знать примерное распределение данных. Если вы не знаете заранее, вы можете использовать сегмент по умолчанию ({.005, .01, .025, .05, .1, .25, .5, 1 , 2.5, 5, 10}) или 2 Несколько сегментов ({1,2,4,8…}) наблюдайте за распределением данных, а затем корректируйте сегменты.
-
Там, где распределение данных более плотное, интервал корзины можно установить более узким, а там, где распределение разреженное, его можно установить более широким.
-
Для большинства данных о задержке он обычно имеет характеристики длинного хвоста, и для него больше подходит использование экспоненциальных сегментов.
-
Верхняя граница начального ведра обычно покрывает около 10% данных, если не обращать внимание на данные заголовка, то верхнюю границу начального ведра можно сделать больше.
-
Если вы хотите более точно рассчитать определенный процентиль, например 90 %, вы можете зашифровать сегменты распределения на уровне 90 % данных, то есть уменьшить интервал между сегментами.
Например, когда я отслеживаю время выполнения некоторых наших задач, я предпочитаю оценивать приблизительную стоимость корзины в соответствии с реальной ситуацией. После выхода в интернет наблюдаю за данными и мониторингом, а затем корректирую корзинку. После нескольких корректировок она должны быть в состоянии быть настроены на более подходящее значение.
Советы по Графане
просмотреть все размеры
Если вы хотите узнать, можете ли вы сгруппировать по другим измерениям, и быстро увидеть, какие измерения доступны, вы можете использовать следующий трюк: оставьте в выражении запроса только имя метрики без каких-либо вычислений и оставьте поле «Легенда» пустым. Это отобразит необработанные данные метрики. Как показано ниже
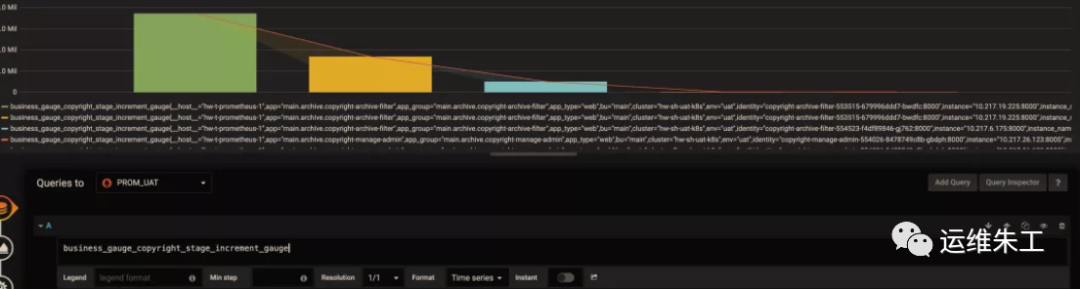
Связь линейки
На панели «Настройки» есть пункт настройки «Подсказка графика», по умолчанию используется «По умолчанию».
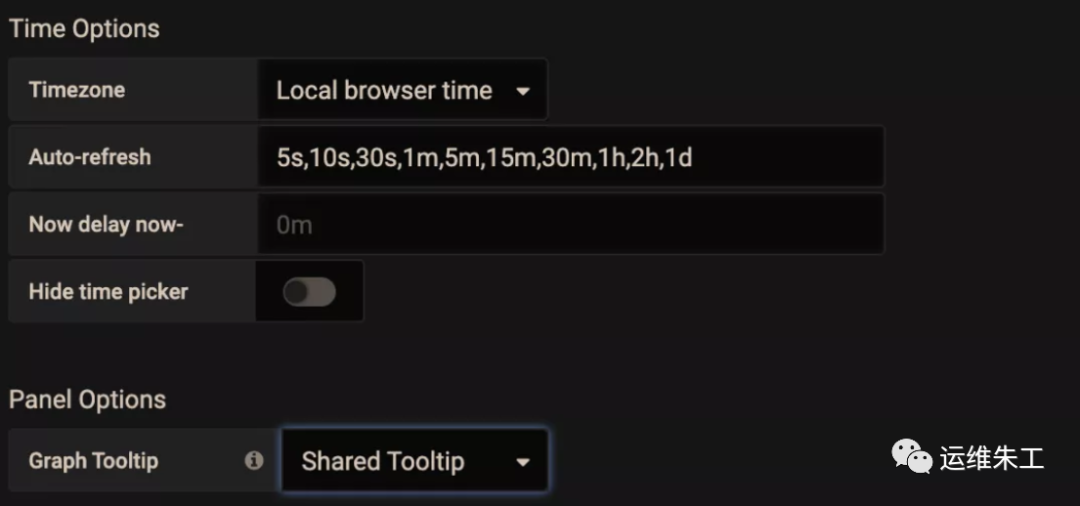
Настройте инструмент графического отображения на «Общее перекрестие» и «Общая подсказка» соответственно, чтобы увидеть эффект. Видно, что шкала может отображаться в связке, что удобно для подтверждения корреляции между двумя показателями при устранении неполадок.
Настройте инструмент графического отображения на Shared Tooltip:
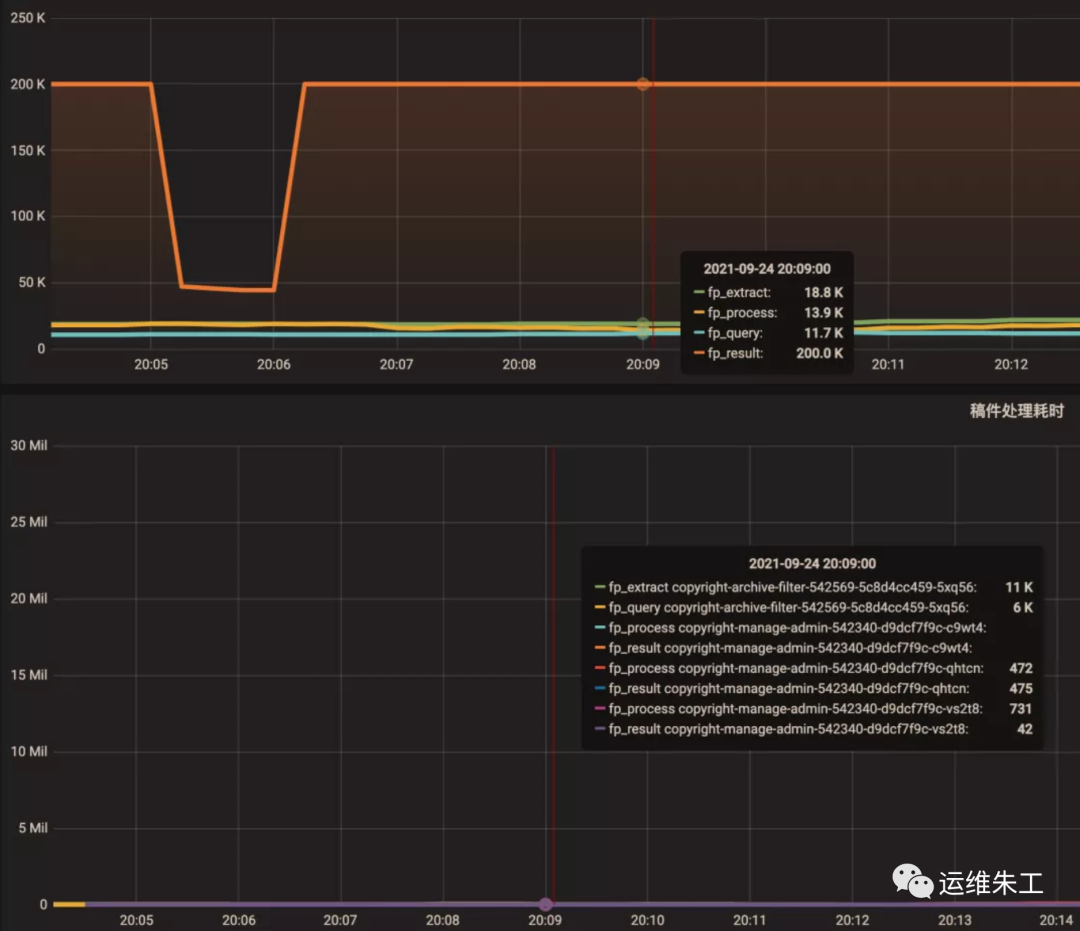
Вам также может понравиться: