Автор: Эйдан Купер
Сборник "Сердце машины"
Сердце Машины Редакционный отдел
Область машинного обучения очень быстро развивалась в последние годы, но наше понимание теории машинного обучения все еще очень ограничено, а экспериментальные эффекты некоторых моделей даже превосходят наше понимание базовой теории.
В настоящее время все больше исследователей в данной области начинают обращать внимание и размышлять над этим вопросом. Недавно ученый по данным по имени Эйдан Купер написал блог, чтобы разобраться в связи между экспериментальными результатами модели и лежащей в ее основе теорией. Ниже приводится исходная запись в блоге:
В области машинного обучения некоторые модели очень эффективны, но мы не совсем уверены, почему. И наоборот, некоторые относительно хорошо изученные области исследований имеют ограниченную применимость на практике. В этой статье рассматриваются достижения в различных областях, основанные на полезности и теоретическом понимании машинного обучения.
«Экспериментальная полезность» здесь — составная мера, учитывающая широту применимости метода, простоту его реализации и, самое главное, насколько он полезен в реальном мире. Некоторые методы не только практичны, но и широко применимы; другие, хотя и мощные, ограничены конкретными областями. Надежные, предсказуемые и не имеющие серьезных недостатков методы считаются более полезными.
Так называемое теоретическое понимание заключается в том, чтобы рассмотреть интерпретируемость модельного метода, то есть какова связь между входом и выходом, как можно получить ожидаемые результаты, каков внутренний механизм метода, а также рассмотреть глубину и полнота литературы, используемой в методе.
Методы с низким уровнем теоретического понимания часто используют в своей реализации эвристику или обширный метод проб и ошибок; методы с высоким уровнем теоретического понимания, как правило, имеют шаблонные реализации с прочной теоретической основой и предсказуемыми результатами. Более простые методы, такие как линейная регрессия, имеют более низкие теоретические верхние границы, в то время как более сложные методы, такие как глубокое обучение, имеют более высокие теоретические верхние границы. Когда дело доходит до глубины и полноты литературы в области, область оценивается по теоретическим верхним границам, принятым областью, которая частично полагается на интуицию.
Мы можем построить матрицу полезности в виде четырех квадрантов, где пересечение осей представляет собой гипотетическую область отсчета со средним пониманием и средней полезностью. Этот подход позволяет нам качественно интерпретировать домены в соответствии с квадрантом, в котором они находятся, как показано на рисунке ниже, домены в данном квадранте могут иметь некоторые или все функции, соответствующие этому квадранту.
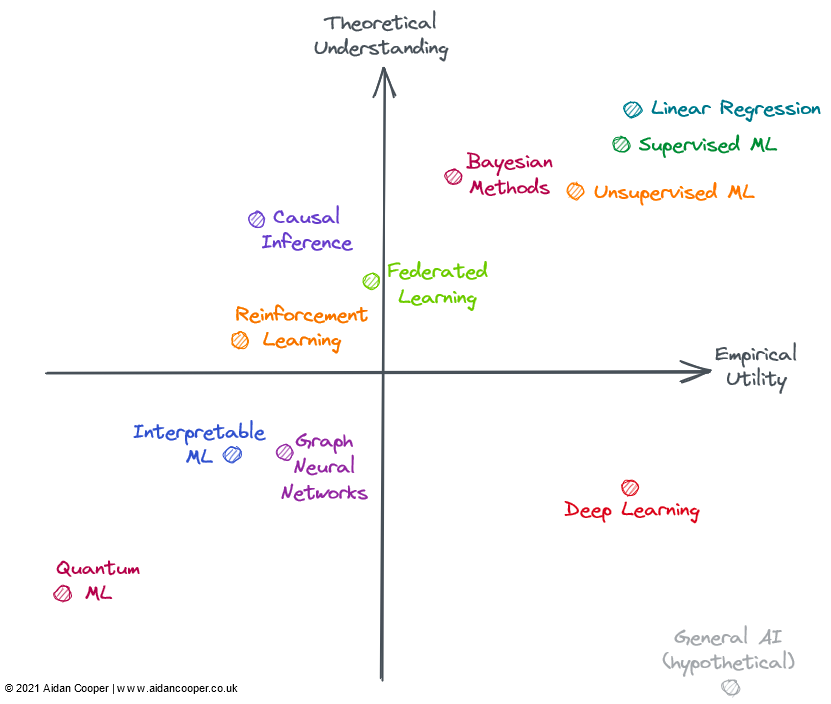
В общем, мы ожидаем, что полезность и понимание будут слабо связаны между собой, что делает методы с высокой степенью теоретического понимания более полезными, чем методы с низкой степенью понимания. Это означает, что большинство полей должны находиться в нижнем левом или правом верхнем квадранте. Вдали от нижнего левого - верхнее правое диагональное поле представляет собой исключение. В общем, практическая полезность должна отставать от теории, потому что требуется время, чтобы превратить зарождающуюся исследовательскую теорию в практическое применение. Так что диагональная линия должна быть выше начала координат, а не прямо через него.
Область машинного обучения в 2022 году
Не все поля на приведенной выше диаграмме полностью охвачены машинным обучением (ML), но все они могут применяться в контексте ML или тесно связаны с ним. Многие из оцениваемых областей пересекаются и не могут быть четко описаны: передовые методы обучения с подкреплением, федеративное обучение и машинное обучение на основе графов часто основаны на глубоком обучении. Поэтому я считаю неглубокие аспекты обучения их теоретической и практической полезностью.
Верхний правый квадрант: высокое понимание, высокая полезность
Линейная регрессия — это простой, понятный и эффективный метод. Хотя его часто недооценивают и упускают из виду. , но широта использования и тщательное теоретическое обоснование помещают его в правый верхний угол рисунка.
Традиционное машинное обучение превратилось в хорошо изученную теоретически и практическую область. Было показано, что сложные алгоритмы машинного обучения, такие как деревья решений с градиентным усилением (GBDT), в целом превосходят линейную регрессию в некоторых сложных задачах прогнозирования. Это, безусловно, относится к проблеме больших данных. Возможно, в теоретическом понимании чрезмерно параметризованных моделей все еще есть пробелы, но внедрение машинного обучения — это деликатный методологический процесс, и, если все сделано правильно, модели могут надежно работать в отрасли.
Однако дополнительная сложность и гибкость приводят к некоторым ошибкам, поэтому я помещаю машинное обучение в левую часть линейной регрессии. В целом машинное обучение с учителем является более совершенным и эффективным, чем его аналог без учителя*, но оба подхода эффективно решают разные проблемные области.
У байесовских методов есть культ практиков, рекламирующих свое превосходство над более популярными классическими статистическими методами. Байесовские модели особенно полезны в определенных ситуациях: когда одних точечных оценок недостаточно, важны оценки неопределенности; когда данные ограничены или отсутствуют в значительной степени; и когда вы понимаете процесс генерации данных, который вы хотите явно включить в свою модель. . Полезность байесовских моделей ограничена тем фактом, что для многих задач точечные оценки достаточно хороши, и люди просто по умолчанию используют небайесовские методы. Что еще более важно, существуют способы количественной оценки неопределенности в традиционном машинном обучении (они используются редко). Часто проще просто применить алгоритмы машинного обучения к данным, не рассматривая механизмы генерации данных и априорные значения. Байесовские модели также требуют больших вычислительных ресурсов и будут более практичными, если теоретические достижения приведут к улучшению методов выборки и аппроксимации.
Нижний правый квадрант: низкое понимание, высокая полезность
Вопреки прогрессу в большинстве областей, глубокое обучение добилось удивительных успехов, хотя теоретическая сторона оказалась принципиально сложной для достижения прогресса. Глубокое обучение воплощает в себе многие характеристики менее известного подхода: модели нестабильны, их трудно надежно построить, настроить на основе слабых эвристик и получить непредсказуемые результаты. Подозрительные методы, такие как «настройка» случайного начального числа, очень распространены, и механизм работы моделей трудно объяснить. Тем не менее, глубокое обучение продолжает развиваться и достигать сверхчеловеческих уровней производительности в таких областях, как компьютерное зрение и обработка естественного языка, открывая мир, наполненный другими непостижимыми задачами, такими как автономное вождение.
Гипотетически общий ИИ будет занимать правый нижний угол, потому что сверхразум по определению находится за пределами человеческого понимания и может быть использован для решения любой задачи. В настоящее время он включен только в качестве мысленного эксперимента.
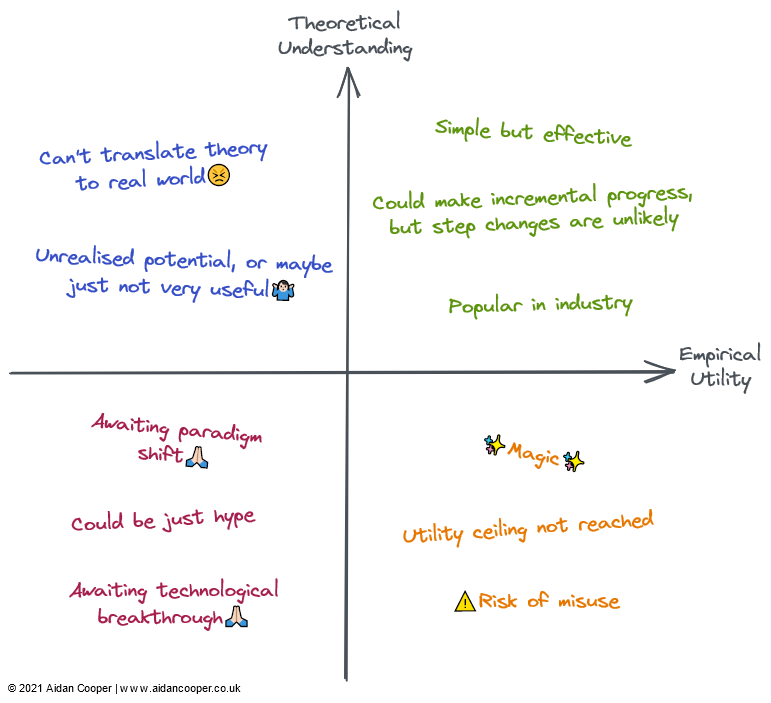
Качественное описание каждого квадранта. Поля могут быть описаны некоторыми или всеми их описаниями в соответствующих областях.
Верхний левый квадрант: высокое понимание, низкая полезность
Большинство форм причинно-следственного вывода не являются машинным обучением, но иногда являются и всегда представляют интерес для прогностических моделей. Причинность можно разделить на рандомизированные контролируемые испытания (РКИ) и более сложные методы причинно-следственного вывода, которые пытаются измерить причинно-следственную связь на основе данных наблюдений. РКИ просты в теории и дают точные результаты, но часто дороги и непрактичны, если не невозможны, для выполнения в реальном мире и, таким образом, имеют ограниченную полезность. Методы каузального вывода, по сути, имитируют РКИ, ничего не делая, что значительно упрощает их выполнение, но имеет много ограничений и подводных камней, которые могут сделать результаты недействительными. В целом причинно-следственная связь остается разочаровывающим поиском, где современные подходы часто не отвечают на вопросы, которые мы хотим задать, если только они не могут быть изучены с помощью рандомизированных контролируемых испытаний или если они не вписываются в определенные рамки (например, как случайный результат " естественный эксперимент»).
Федеративное обучение (FL) — классная концепция, которой уделялось мало внимания — вероятно, потому, что ее самое привлекательное приложение необходимо распространять на большое количество смартфонов, поэтому FL на самом деле изучают только два игрока: Apple и Google. Существуют и другие варианты использования FL, такие как объединение закрытых наборов данных, но при координации этих инициатив возникают политические и логистические проблемы, ограничивающие их полезность на практике. Тем не менее, для того, что звучит как причудливая концепция (примерно можно резюмировать так: «Приведите модель к данным, а не данные к модели»), FL действителен и имеет приложения в таких областях, как предсказание текста клавиатуры и персонализированные рекомендации по новостям. Практические истории успеха Базовая теория и методы, лежащие в основе FL, кажутся достаточными для более широкого использования FL.
Обучение с подкреплением (RL) позволило достичь беспрецедентного уровня компетентности в таких играх, как шахматы, го, покер и дота. Но за пределами видеоигр и сред моделирования обучение с подкреплением еще предстоит убедительно перенести в реальные приложения. Предполагалось, что робототехника станет следующей границей RL, но этого не произошло — реальность казалась более сложной, чем сильно ограниченная игрушечная среда. Тем не менее, достижения RL до сих пор вдохновляют, и тот, кто действительно любит шахматы, может подумать, что его полезность должна быть выше. Я хотел бы увидеть, как RL реализует некоторые из своих потенциальных практических приложений, прежде чем помещать его в правильную сторону матрицы.
Нижний левый квадрант: низкое понимание, низкая полезность
Графовые нейронные сети (GNN) в настоящее время являются очень популярной областью машинного обучения с многообещающими результатами во многих областях. Но для многих из этих примеров неясно, лучше ли GNN, чем альтернативы, которые используют более традиционные структурированные данные в сочетании с архитектурами глубокого обучения. Данные, которые естественным образом структурированы в виде графа, например, молекулы в химико-информатике, по-видимому, дают более убедительные результаты GNN (хотя они, как правило, не так хороши, как методы, не связанные с графами). По сравнению с большинством областей, существует большая разница между инструментами с открытым исходным кодом, используемыми для обучения GNN в масштабе, и внутренними инструментами, используемыми в промышленности, что ограничивает жизнеспособность крупных GNN за пределами этих огороженных садов. Сложность и широта области предполагают высокую теоретическую верхнюю границу, поэтому у GNN должно быть пространство для развития и убедительной демонстрации преимуществ для определенных задач, что приведет к большей полезности. GNN также могут извлечь выгоду из технологических достижений, поскольку в настоящее время графики не вписываются естественным образом в существующее вычислительное оборудование.
Интерпретируемое машинное обучение (IML) является важной и многообещающей областью, которая продолжает привлекать внимание. Такие методы, как SHAP и LIME, стали действительно полезными инструментами для изучения моделей машинного обучения. Тем не менее, из-за ограниченного применения, полезность существующих методов еще не полностью реализована - надежные передовые методы и рекомендации по внедрению не установлены. Однако основная слабость IML в настоящее время заключается в том, что он не решает причинно-следственных проблем, которые нас действительно интересуют. IML объясняет, как модель делает прогнозы, но не объясняет, как базовые данные причинно связаны с ними (хотя это часто неправильно интерпретируется). До тех пор, пока не будет достигнут значительный теоретический прогресс, законное использование IML в основном ограничивается отладкой/мониторингом моделей и генерацией гипотез.
Квантовое машинное обучение (QML) находится далеко за пределами моей рулевой рубки, но в настоящее время кажется гипотетическим упражнением, терпеливо ожидающим появления жизнеспособного квантового компьютера. До этого QML тривиально располагался в левом нижнем углу.
Постепенные улучшения, технологические скачки и сдвиги парадигмы
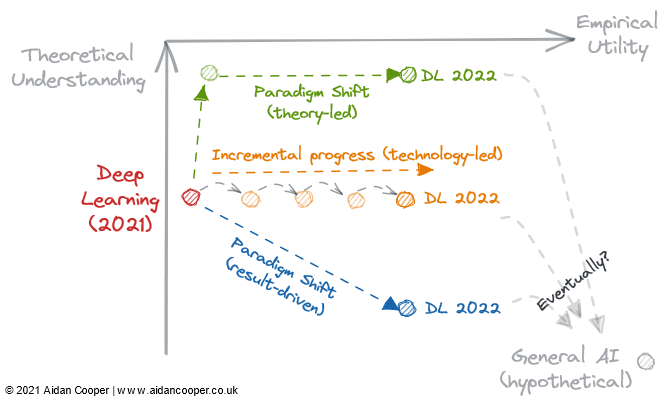
Есть три основных механизма, с помощью которых поле пересекает теоретическое понимание и эмпирическую матрицу полезности (рис. 2).
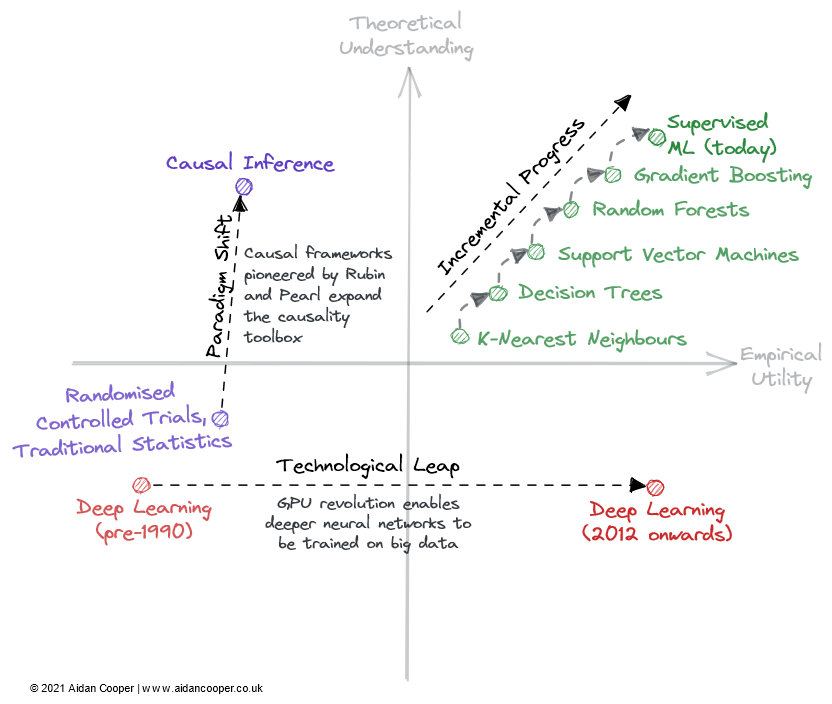
Наглядный пример того, как поля могут пересекать матрицу.
Инкрементальный прогресс — это медленный и устойчивый прогресс, который перемещает поле вверх на дюймы в правой части матрицы. Хорошим примером является контролируемое машинное обучение последних нескольких десятилетий, когда все более эффективные алгоритмы прогнозирования были усовершенствованы и приняты, что дало нам мощный набор инструментов, который мы любим сегодня. Постепенный прогресс — это статус-кво во всех зрелых областях, за исключением периодов большего движения из-за технологических скачков и смены парадигмы.
В некоторых областях произошли резкие изменения в научном прогрессе из-за скачков в технологиях. Область *глубокого обучения* не раскрывается своими теоретическими основами, которые были обнаружены более чем за 20 лет до бума глубокого обучения 2010-х годов — именно параллельная обработка на базе графических процессоров потребительского уровня способствовала ее возрождению. Технологические скачки обычно проявляются как скачки вправо по оси эмпирической полезности. Однако не все технологические достижения являются скачками. Глубокое обучение сегодня характеризуется постепенным прогрессом за счет обучения все более и более крупных моделей с использованием все большей вычислительной мощности и все более специализированного оборудования.
Конечным механизмом научного прогресса в этих рамках является смена парадигмы. Как указывает Томас Кун в своей книге «Структура научных революций», сдвиг парадигмы представляет собой важные изменения в фундаментальных концепциях и экспериментальных практиках научных дисциплин. Одним из таких примеров является причинно-следственная структура, впервые разработанная Дональдом Рубином и Джудеей Перл, которая поднимает область причинно-следственной связи от рандомизированных контролируемых испытаний и традиционного статистического анализа до более мощной математической дисциплины в форме причинного вывода. Сдвиги парадигмы часто проявляются как движение вверх в понимании, которое может следовать или сопровождаться увеличением полезности.
Однако сдвиг парадигмы может проходить по матрице в любом направлении. Когда нейронные сети (а впоследствии и глубокие нейронные сети) утвердились в качестве отдельной парадигмы от традиционного машинного обучения, это изначально соответствовало снижению полезности и понимания. Таким образом, многие новые области ответвились от более устоявшихся областей исследований.
Научная революция в прогнозировании и глубоком обучении
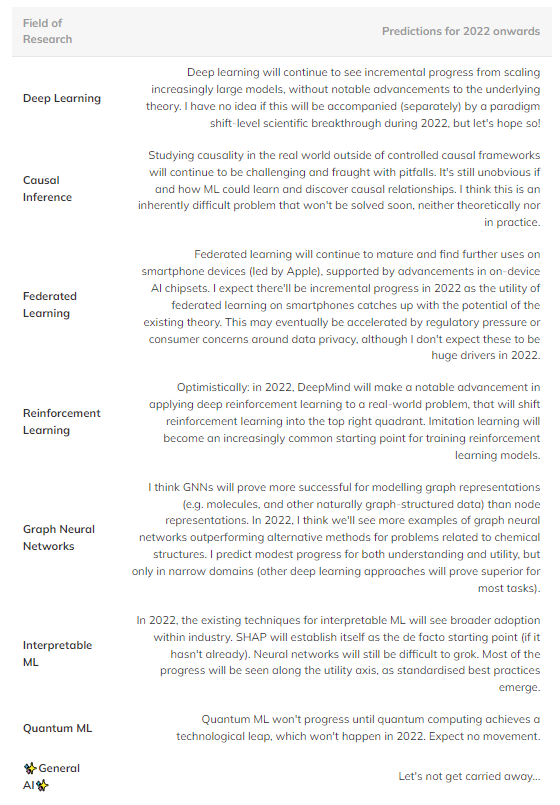
Подводя итог, вот несколько спекулятивных прогнозов, которые, как мне кажется, могут произойти в будущем (таблица 1). Поля в верхнем правом квадранте опущены, поскольку они слишком развиты, чтобы увидеть значительный прогресс.
Таблица 1: Прогноз будущего прогресса в нескольких основных областях машинного обучения.
Однако наблюдения, более важные, чем то, как развиваются отдельные поля, являются общей тенденцией в эмпиризме и растущей готовностью признать всестороннее теоретическое понимание.
Исторически сложилось так, что сначала появляются теории (гипотезы), а затем формулируются идеи. Но глубокое обучение положило начало новому научному процессу, который переворачивает все с ног на голову. Тем не менее ожидается, что методы продемонстрируют современную производительность задолго до того, как люди сосредоточатся на теории. Эмпирические результаты превыше всего, теория необязательна.
Это привело к широкому использованию систем в исследованиях машинного обучения, в результате чего были получены самые современные результаты за счет простого изменения существующих методов и использования случайности для достижения превосходства над базовыми уровнями, а не значимого продвижения теории в этой области. Но, возможно, это цена, которую мы платим за новую волну бума машинного обучения.
Рисунок 3: 3 потенциальных траектории развития глубокого обучения в 2022 году.
2022 год может стать переломным моментом, если глубокое обучение станет необратимо ориентированным на результат процессом и сделает теоретическое понимание необязательным. Мы должны рассмотреть следующие вопросы:
Позволят ли теоретические прорывы нашему пониманию догнать практичность и превратить глубокое обучение в более структурированную дисциплину, подобную традиционному машинному обучению?
Достаточно ли существующей литературы по глубокому обучению, чтобы полезность увеличивалась до бесконечности, просто за счет масштабирования все более и более крупных моделей?
Или эмпирический прорыв приведет нас дальше по кроличьей норе к новой парадигме повышенной полезности, даже если мы знаем о ней меньше?
Приводит ли какой-либо из этих путей к искусственному общему интеллекту? Время покажет.
Исходная ссылка: https://www.aidancooper.co.uk/utility-vs-understanding/?continueFlag=b96fa8ed72dfc82b777e51b7e954c7dc

© КОНЕЦ
Для перепечатки, пожалуйста, свяжитесь с этим официальным аккаунтом для авторизации
Внесите свой вклад или запросите освещение: [email protected]